Overview
This R package provides easy access to Antarctic geographic place name information, and tools for working with those names.
The authoritative source of place names in Antarctica is the Composite Gazetteer of Antarctica (CGA), which is produced by the Scientific Committee on Antarctic Research (SCAR). The CGA consists of approximately 37,000 names corresponding to 19,000 distinct features. It covers features south of 60 °S, including terrestrial and undersea or under-ice.
There is no single naming authority responsible for place names in Antarctica because it does not fall under the sovereignty of any one nation. In general, individual countries have administrative bodies that are responsible for their national policy on, and authorisation and use of, Antarctic names. The CGA is a compilation of place names that have been submitted by representatives of national names committees from 22 countries.
The composite nature of the CGA means that there are often multiple names associated with a given feature. Consider using the an_preferred() function for resolving a single name per feature.
For more information, see the CGA home page. The CGA was begun in 1992. Since 2008, Italy and Australia have jointly managed the CGA, the former taking care of the editing, the latter maintaining the database and website. The SCAR Standing Committee on Antarctic Geographic Information (SCAGI) coordinates the project. This R package is a product of the SCAR Expert Group on Antarctic Biodiversity Informatics and SCAGI.
Citing
The SCAR Composite Gazetteer of Antarctica is made available under a CC-BY license. If you use it, please cite it:
Composite Gazetteer of Antarctica, Scientific Committee on Antarctic Research. GCMD Metadata (http://gcmd.nasa.gov/records/SCAR_Gazetteer.html)
Installing
install.packages("remotes")
remotes::install_github("ropensci/antanym")Example usage
Start by fetching the names data from the host server. Here we use a temporary cache so that we can re-load it later in the session without needing to re-download it:
How many names do we have in total?
nrow(g)
#> [1] 39162Corresponding to how many distinct features?
Find names starting with “Slom”:
an_filter(g, query = "^Slom")[, c("place_name", "longitude", "latitude")]
#> # A tibble: 3 × 3
#> place_name longitude latitude
#> <chr> <dbl> <dbl>
#> 1 Sloman Glacier -68.6 -67.7
#> 2 Sloman Glacier -68.6 -67.7
#> 3 Slomer Cove -59.4 -63.8Find islands within 20km of 100 °E, 66 °S:
nms <- an_near(an_filter(g, feature_type = "Island"), loc = c(100, -66), max_distance = 20)
## or equivalently, using the pipe operator
nms <- g %>% an_filter(feature_type = "Island") %>% an_near(loc = c(100, -66), max_distance = 20)
nms[, c("place_name", "longitude", "latitude")]
#> # A tibble: 3 × 3
#> place_name longitude latitude
#> <chr> <dbl> <dbl>
#> 1 Foster Island 100. -66.1
#> 2 Severnyj holm 100. -66.1
#> 3 Foster Island 100. -66.1Resolving multiple names per feature
As noted above, the CGA is a composite gazetteer and so there are often multiple names associated with a given feature. For example, we can see all names associated with feature 1589 (Booth Island) and the country of origin of each name:
an_filter(g, feature_ids = 1589)[, c("place_name", "origin")]
#> # A tibble: 7 × 2
#> place_name origin
#> <chr> <chr>
#> 1 Booth, isla Argentina
#> 2 Wandel, Ile Belgium
#> 3 Booth, Isla Chile
#> 4 Boothinsel Germany
#> 5 Booth Island United Kingdom
#> 6 Booth Island Russia
#> 7 Booth Island United States of AmericaThe an_preferred function can help with finding one name per feature. It takes an origin parameter that specifies one or more preferred naming authorities (countries or organisations). For features that have multiple names (e.g. have been named by multiple countries) a single name will be chosen, preferring names from the specified naming authorities where possible.
We start with 39162 names in the full CGA, corresponding to 20134 distinct features. Choose one name per feature, preferring the Polish name where there is one, and the German name as a second preference:
g <- an_preferred(g, origin = c("Poland", "Germany"))Now we have 20134 names in our data frame, corresponding to the same 20134 distinct features.
Name suggestions
Antanym includes an experimental function that will suggest which features might be best to to name on a given map. These suggestions are based on maps prepared by expert cartographers, and the features that were explicitly named on those maps.
See the package vignette and the an_suggest function for more information.
Map example
A leaflet app using Mercator projection and clustered markers for place names.
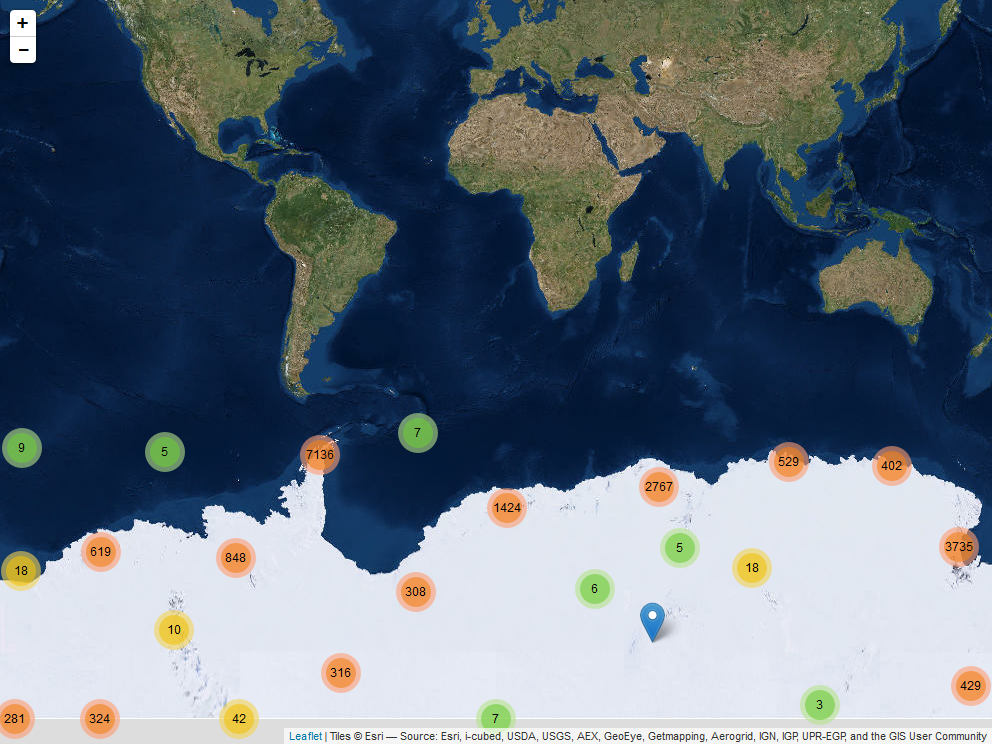
See the antanym-demo repository for the source code.
Other packages
The geonames package also provides access to geographic place names, including from the SCAR Composite Gazetteer. If you need global place name coverage, geonames may be a better option. However, the composite nature of the CGA is not particularly well suited to geonames, and at the time of writing the geonames database did not include the most current version of the CGA. The geonames package requires a login for some functionality, and because it makes calls to api.geonames.org it isn’t easily used while offline.
