The hunspell package: High-Performance Stemmer, Tokenizer, and Spell Checker for R
2024-08-07
Source:vignettes/intro.Rmd
intro.RmdHunspell is the spell checker library used by LibreOffice, OpenOffice, Mozilla Firefox, Google Chrome, Mac OS-X, InDesign, Opera, RStudio and many others. It provides a system for tokenizing, stemming and spelling in almost any language or alphabet. The R package exposes both the high-level spell-checker as well as low-level stemmers and tokenizers which analyze or extract individual words from various formats (text, html, xml, latex).
Hunspell uses a special dictionary format that defines which
characters, words and conjugations are valid in a given language. The
examples below use the (default) "en_US" dictionary.
However each function can be used in another language by setting a
custom dictionary in the dict parameter. See the section on
dictionaries below.
Spell Checking
Spell checking text consists of the following steps:
- Parse a document by extracting (tokenizing) words that we want to check
- Analyze each word by breaking it down in it’s root (stemming) and conjugation affix
- Lookup in a dictionary if the word+affix combination if valid for your language
- (optional) For incorrect words, suggest corrections by finding similar (correct) words in the dictionary
We can do each these steps manually or have Hunspell do them automatically.
Check Individual Words
The hunspell_check and hunspell_suggest
functions can test individual words for correctness, and suggest similar
(correct) words that look similar to the given (incorrect) word.
library(hunspell)
# Check individual words
words <- c("beer", "wiskey", "wine")
correct <- hunspell_check(words)
print(correct)[1] TRUE FALSE TRUE
# Find suggestions for incorrect words
hunspell_suggest(words[!correct])[[1]]
[1] "whiskey" "whiskery"Check Documents
In practice we often want to spell check an entire document at once
by searching for incorrect words. This is done using the
hunspell function:
[1] "neccessairy" "langauge"
hunspell_suggest(bad[[1]])[[1]]
[1] "necessary" "necessarily"
[[2]]
[1] "language" "melange" Besides plain text, hunspell supports various document
formats, such as html or latex:
download.file("https://arxiv.org/e-print/1406.4806v1", "1406.4806v1.tar.gz", mode = "wb")
untar("1406.4806v1.tar.gz", "content.tex")
text <- readLines("content.tex", warn = FALSE)
bad_words <- hunspell(text, format = "latex")
sort(unique(unlist(bad_words))) [1] "auth" "CORBA" "cpu" "cran" "cron"
[6] "css" "csv" "CTRL" "DCOM" "de"
[11] "dec" "decompositions" "dir" "DOM" "DSL"
[16] "eol" "ESC" "facto" "grDevices" "httpuv"
[21] "ignorable" "interoperable" "JRI" "js" "json"
[26] "jsonlite" "knitr" "md" "memcached" "mydata"
[31] "myfile" "nondegenerateness" "OAuth" "ocpu" "opencpu"
[36] "OpenCPU" "pandoc" "pb" "php" "png"
[41] "prescripted" "priori" "protobuf" "rApache" "rda"
[46] "rds" "reproducibility" "Reproducibility" "RinRuby" "RInside"
[51] "rlm" "rmd" "rnorm" "rnw" "RPC"
[56] "RProtoBuf" "rpy" "Rserve" "RStudio" "saveRDS"
[61] "scalability" "scalable" "schemas" "se" "sep"
[66] "SIGINT" "STATA" "stateful" "Stateful" "statefulness"
[71] "stdout" "STDOUT" "suboptimal" "svg" "sweave"
[76] "tex" "texi" "tmp" "toJSON" "urlencoded"
[81] "www" "xyz" Check PDF files
Use the text-extraction from the pdftools package to
spell check text from PDF files!
text <- pdftools::pdf_text('https://www.gnu.org/licenses/quick-guide-gplv3.pdf')
bad_words <- hunspell(text)
sort(unique(unlist(bad_words))) [1] "Affero" "AGPLed" "cryptographic" "DRM" "fsf" "GPLed" "GPLv"
[8] "ISC" "OpenSolaris’" "opments" "tivoization" "Tivoization" "tributing" "users’" Check Manual Pages
The spelling package builds on hunspell and has a
wrapper to spell-check manual pages from R packages. Results might
contain a lot of false positives for technical jargon, but you might
also catch a typo or two. Point it to the root of your source
package:
spelling::spell_check_package("~/workspace/V8") WORD FOUND IN
ECMA V8.Rd:16, description:2,4
ECMAScript description:2
emscripten description:5
htmlwidgets JS.Rd:16
JSON V8.Rd:33,38,39,57,58,59,120
jsonlite V8.Rd:42
Ooms V8.Rd:41,120
Xie JS.Rd:26
Yihui JS.Rd:26Morphological Analysis
In order to lookup a word in a dictionary, hunspell needs to break it
down in a stem (stemming) and conjugation affix. The
hunspell function does this automatically but we can also
do it manually.
Stemming Words
The hunspell_stem looks up words from the dictionary
which match the root of the given word. Note that the function returns a
list because some words can have multiple matches.
# Stemming
words <- c("love", "loving", "lovingly", "loved", "lover", "lovely")
hunspell_stem(words)[[1]]
[1] "love"
[[2]]
[1] "loving" "love"
[[3]]
[1] "loving"
[[4]]
[1] "loved" "love"
[[5]]
[1] "lover" "love"
[[6]]
[1] "lovely" "love" Analyzing Words
The hunspell_analyze function is similar, but it returns
both the stem and the affix syntax of the word:
hunspell_analyze(words)[[1]]
[1] " st:love"
[[2]]
[1] " st:loving" " st:love fl:G"
[[3]]
[1] " st:loving fl:Y"
[[4]]
[1] " st:loved" " st:love fl:D"
[[5]]
[1] " st:lover" " st:love fl:R"
[[6]]
[1] " st:lovely" " st:love fl:Y"Tokenizing
To support spell checking on documents, Hunspell includes parsers for various document formats, including text, html, xml, man or latex. The Hunspell package also exposes these tokenizers directly so they can be used for other application than spell checking.
text <- readLines("content.tex", warn = FALSE)
allwords <- hunspell_parse(text, format = "latex")
# Third line (title) only
print(allwords[[3]]) [1] "The" "OpenCPU" "System" "Towards" "a" "Universal" "Interface" "for"
[9] "Scientific" "Computing" "through" "Separation" "of" "Concerns" Summarizing Text
In text analysis we often want to summarize text via it’s stems. For example we can count words for display in a wordcloud:
allwords <- hunspell_parse(janeaustenr::prideprejudice)
stems <- unlist(hunspell_stem(unlist(allwords)))
words <- sort(table(stems), decreasing = TRUE)
print(head(words, 30))stems
the to of and a i h I in was she
4402 4305 3611 3585 3135 2929 2233 2069 1881 1846 1711
it that not you he hi be had Mr for with
1640 1579 1429 1366 1336 1271 1241 1177 1129 1064 1053
but have on at him my by Elizabeth
1002 938 931 787 764 719 636 635 Most of these are stop words. Let’s filter these out:
df <- as.data.frame(words)
df$stems <- as.character(df$stems)
stops <- df$stems %in% stopwords::stopwords(source="stopwords-iso")
wcdata <- head(df[!stops,], 150)
print(wcdata, max = 40) stems Freq
8 I 2069
20 Mr 1129
30 Elizabeth 635
48 Darcy 418
63 sister 294
64 Jane 292
68 Miss 281
72 lady 265
76 It 247
79 He 235
85 time 224
87 ha 221
96 aft 200
105 happy 183
107 Collins 180
112 bee 175
115 day 174
117 Lydia 171
119 feel 167
120 friend 166
[ reached 'max' / getOption("max.print") -- omitted 130 rows ]
library(wordcloud2)
names(wcdata) <- c("word", "freq")
wcdata$freq <- (wcdata$freq)^(2/3)
wordcloud2(wcdata)Error in loadNamespace(name): there is no package called 'webshot'Hunspell Dictionaries
Hunspell is based on MySpell and is backward-compatible with MySpell and aspell dictionaries. Chances are your dictionaries in your language are already available on your system!
A Hunspell dictionary consists of two files:
- The
[lang].afffile specifies the affix syntax for the language - The
[lang].dicfile contains a wordlist formatted using syntax from the aff file.
Typically both files are located in the same directory and share the
same filename, for example en_GB.aff and
en_GB.dic. The list_dictionaries() function
lists available dictionaries in the current directory and standard
system paths where dictionaries are usually installed.
[1] "en_AU" "en_CA" "en_GB" "en_US"The dictionary function is then used to load any of
these available dictionaries:
dictionary("en_GB")<hunspell dictionary>
affix: /Users/jeroen/Library/R/arm64/4.4/library/hunspell/dict/en_GB.aff
dictionary: /Users/jeroen/Library/R/arm64/4.4/library/hunspell/dict/en_GB.dic
encoding: UTF-8
wordchars: ’
added: 0 custom wordsIf the files are not in one of the standard paths you can also specify the full path to either or both the dic and aff file:
dutch <- dictionary("~/workspace/Dictionaries/Dutch.dic")
print(dutch)<hunspell dictionary>
affix: /Users/jeroen/workspace/Dictionaries/Dutch.aff
dictionary: /Users/jeroen/workspace/Dictionaries/Dutch.dic
encoding: UTF-8
wordchars: '-./0123456789\ij’Setting a Language
The hunspell R package includes dictionaries for en_US
and en_GB. So if you you don’t speak en_US you
can always switch to the British English:
hunspell("My favourite colour to visualise is grey")[[1]]
[1] "favourite" "colour" "visualise" "grey"
hunspell("My favourite colour to visualise is grey", dict = 'en_GB')[[1]]
character(0)If you want to use another language you need to make sure that the
dictionary is available from your system. The dictionary
function is used to read in dictionary.
dutch <- dictionary("~/workspace/Dictionaries/Dutch.dic")
hunspell("Hij heeft de klok wel horen luiden, maar weet niet waar de klepel hangt", dict = dutch)Note that if the dict argument is a string, it will be
passed on to the dictionary function.
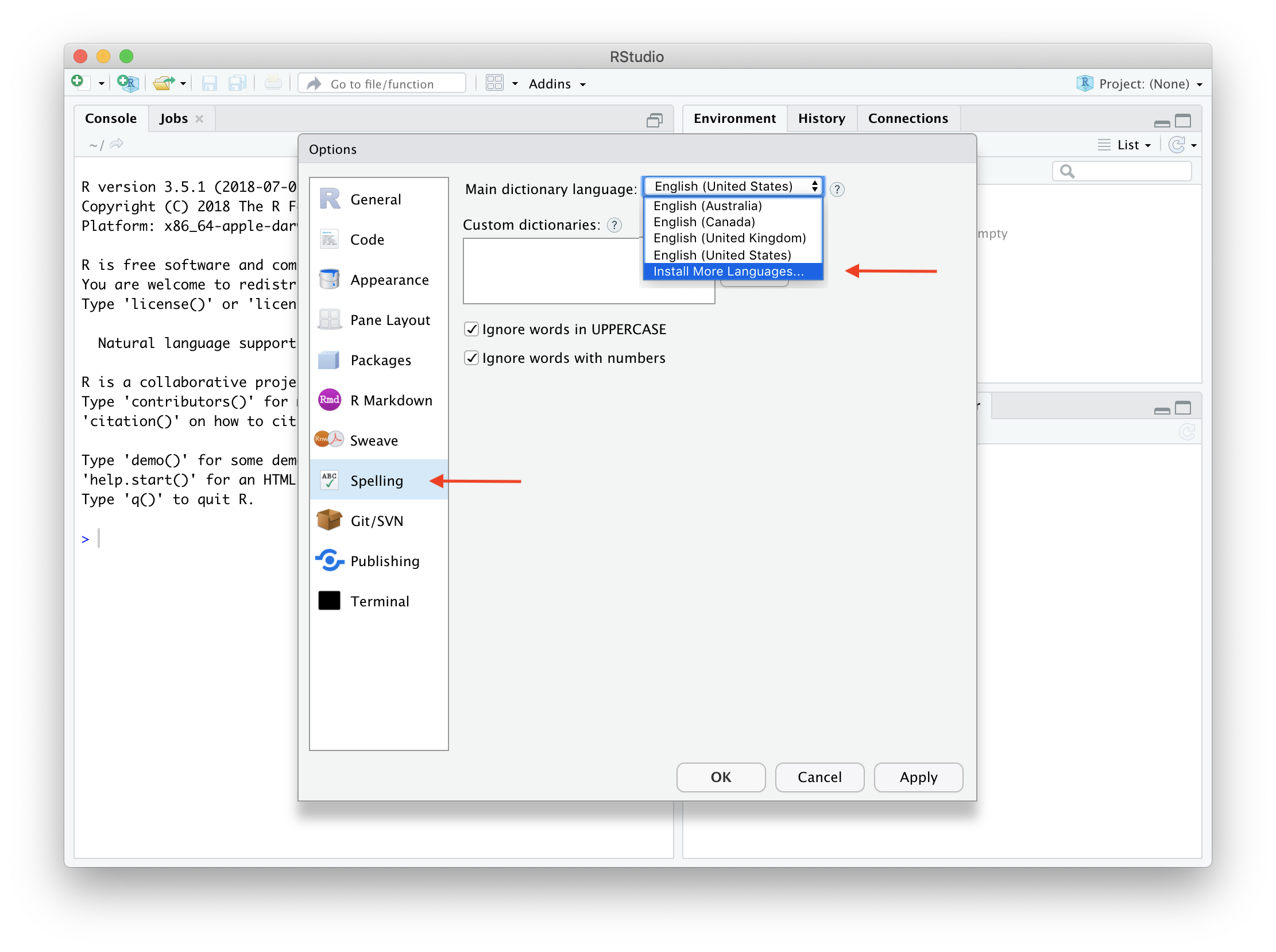
Installing Dictionaries in RStudio
RStudio users can install various dictionaries via the “Global
Options” menu of the IDE. Once these dictionaries are installed they
become available to the hunspell and spelling
package as well.
Dictionaries on Linux
The best way to install dictionaries on Linux is via
the system package manager. For example on if you would like to install
the Austrian-German dictionary on Debian or
Ubuntu you either need the hunspell-de-at
or myspell-de-at
package:
On Fedora and CentOS /
RHEL all German dialects are included with the hunspell-de
package
After installing this you should be able to load the dictionary:
dict <- dictionary('de_AT')If that didn’t work, verify that the dictionary files were installed
in one of the system directories (usually
/usr/share/myspell or
/usr/share/hunspell).
Custom Dictionaries
If your system does not provide standard dictionaries you need to download them yourself. There are a lot of places that provide quality dictionaries.
On OS-X it is recommended
to put the files in ~/Library/Spelling/ or
/Library/Spelling/. However you can also put them in your
project working directory, or any of the other standard locations. If
you wish to store your dictionaries somewhere else, you can make
hunspell find them by setting the DICPATH environment
variable. The hunspell:::dicpath() shows which locations
your system searches:
Sys.setenv(DICPATH = "/my/custom/hunspell/dir")
hunspell:::dicpath() [1] "/my/custom/hunspell/dir"
[2] "/Users/jeroen/Library/R/arm64/4.4/library/hunspell/dict"
[3] "/Users/jeroen/Library/Spelling"
[4] "/usr/local/share/hunspell"
[5] "/usr/local/share/myspell"
[6] "/usr/local/share/myspell/dicts"
[7] "/usr/share/hunspell"
[8] "/usr/share/myspell"
[9] "/usr/share/myspell/dicts"
[10] "/Library/Spelling"
[11] "/Applications/RStudio.app/Contents/Resources/app/resources/dictionaries"
[12] "~/.config/rstudio/dictionaries/languages-system"
[13] "~/.config/rstudio/dictionaries/languages-user"