Note about the effects of the API changes.
This is a good example of life under the new version of the API, where we have to make more than one call to get the same data as before. This assumes that we have already received an API key and have set the environmental variable (see the API Changes page). Maybe even keep the old page around for comparison? For now the original Top Assignees page is here.
Intention:
The original version of this page used the patent’s application date in the plot below. In the new version of the API there is a patent_year (the year the patent was granted, already of type integer) that we’ll use. Trouble is that the count is nested inside the patents structure, not inside the nested assignees. Fortunately both nested structures have patent_id as a field so we can join them to get the data we need.In the original version of this page we searched for database (singular) but now that produces a result set of over 10,000 rows. Instead, we’ll search for databases (plural) which will make our result set smaller.
We start by calling the patent endpoint to get the patents where “databases” is in the title or abstract and there is an assignee. We make a subsequent call to the assignee endpoint to get assignee_num_patents (total number of patents) for the top 75 assignees, then we blend in the assignee_num_patents and compute the percentages. Then life, and the script, goes on as normal (as the original script did).
The following is a quick analysis of the top organizations patenting in the field of databases.
- The first step is to download the relevant data fields from the PatentsView API:
library(patentsview)
library(dplyr)
library(highcharter)
library(DT)
library(knitr)
# We first need to write a query. Our query will look for "databases" in either
# the patent title or abstract...Note, this isn't a terribly good way to ID our
# patents, but it will work for the purpose of demonstration. Users who are
# interested in writing higher-quality queries could consult the large body of
# research that has been done in field of patent document retrieval.
query <- with_qfuns(
and(
neq("assignees.assignee_organization" = ""),
or(
text_phrase(patent_abstract = "databases"),
contains(patent_title = "databases")
)
)
)
query
#> {"_and":[{"_neq":{"assignees.assignee_organization":""}},{"_or":[{"_text_phrase":{"patent_abstract":"databases"}},{"_contains":{"patent_title":"databases"}}]}]}
# Create a list of the fields we'll need for the analysis.
# We'll request both "patent_earliest_application_date" and
# "applications.filing_date" so that either could be used
# in the plot below
fields <- c(
"patent_id", "patent_date", "patent_year", "patent_earliest_application_date",
"patent_num_us_patents_cited", "application.filing_date",
"assignees" # the assignee fields come back in a nested object
)
# Send an HTTP request to the PatentsView API to get the data
pv_out <- search_pv(query, fields = fields, all_pages = TRUE, size = 1000)
pv_out
#> $data
#> #### A list with a single data frame (with list column(s) inside) on patents level:
#>
#> List of 1
#> $ patents:'data.frame': 9538 obs. of 7 variables:
#> ..$ patent_id : chr [1:9538] "10000987" ...
#> ..$ patent_date : chr [1:9538] "2018-06-19" ...
#> ..$ patent_year : int [1:9538] 2018 2018 ...
#> ..$ patent_earliest_application_date: chr [1:9538] "2014-02-20" ...
#> ..$ patent_num_us_patents_cited : int [1:9538] 163 7 ...
#> ..$ application :List of 9538
#> ..$ assignees :List of 9538
#>
#> $query_results
#> #### Distinct entity counts across all downloadable pages of output:
#>
#> total_hits = 9,538- Now let’s identify who the top assignees are based on how many patents they have in our data set. We’ll also calculate how many total patents these assignees have and what fraction of their total patents relate to databases.
# Unnest the data frames that are stored in the assignee list column
dl <- unnest_pv_data(pv_out$data, "patent_id")
dl
#> List of 3
#> $ application:'data.frame': 9538 obs. of 7 variables:
#> ..$ patent_id : chr [1:9538] "10000987" ...
#> ..$ application_id : chr [1:9538] "14/185552" ...
#> ..$ application_type: chr [1:9538] "14" ...
#> ..$ filing_date : chr [1:9538] "2014-02-20" ...
#> ..$ series_code : chr [1:9538] "14" ...
#> ..$ rule_47_flag : logi [1:9538] TRUE ...
#> ..$ filing_type : chr [1:9538] "14" ...
#> $ assignees :'data.frame': 9027 obs. of 12 variables:
#> ..$ patent_id : chr [1:9027] "10000987" ...
#> ..$ assignee : chr [1:9027] "https://search.patentsvie"..
#> ..$ assignee_id : chr [1:9027] "e07b29f0-1b4d-4181-bd2d-0"..
#> ..$ assignee_type : chr [1:9027] "2" ...
#> ..$ assignee_individual_name_first: chr [1:9027] NA ...
#> ..$ assignee_individual_name_last : chr [1:9027] NA ...
#> ..$ assignee_organization : chr [1:9027] "National Oilwell Varco, L"..
#> ..$ assignee_location_id : chr [1:9027] "4e49a0a0-16c8-11ed-9b5f-1"..
#> ..$ assignee_city : chr [1:9027] "Houston" ...
#> ..$ assignee_state : chr [1:9027] "TX" ...
#> ..$ assignee_country : chr [1:9027] "US" ...
#> ..$ assignee_sequence : int [1:9027] 0 0 ...
#> $ patents :'data.frame': 9538 obs. of 5 variables:
#> ..$ patent_id : chr [1:9538] "10000987" ...
#> ..$ patent_date : chr [1:9538] "2018-06-19" ...
#> ..$ patent_year : int [1:9538] 2018 2018 ...
#> ..$ patent_earliest_application_date: chr [1:9538] "2014-02-20" ...
#> ..$ patent_num_us_patents_cited : int [1:9538] 163 7 ...
# We don't get the assignee_total_num_patents back from the patent endpoint any longer.
# We'll have to make a call to the assignee endpoint once we know who the top 75
# assignees are.
# We requested assignees.assignee_id but it comes back in the assignees object
# with key "assignee" (the _id clipped off) and a GUID looking value ex:
# https://search.patentsview.org/api/v1/assignee/4e49a0a0-16c8-11ed-9b5f-1234bde3cd05/
# We want to parse out the assignee_ids, ex: 4e49a0a0-16c8-11ed-9b5f-1234bde3cd05
# (The API's documetation shows that the assignee URL parameter is the assignee_id)
# Create a data frame with the top 75 assignees:
top_asgns <-
dl$assignees %>%
mutate(assignee_id = sub(".*/([0-9a-f-]+)/$", "\\1", assignee)) %>%
group_by(assignee_organization, assignee_id) %>%
summarise(db_pats = n()) %>%
ungroup() %>%
arrange(desc(db_pats)) %>%
slice(1:75)
# Now that we have the assignee_id's, we can make a single call to the assignee
# endpoint to get the total number of patents for each of our top_asgns. (One
# call rather than 75 calls using the unparsed "assignee" URLs)
assignee_query = qry_funs$eq(assignee_id = top_asgns$assignee_id)
assignee_fields <- c(
"assignee_id", "assignee_organization", "assignee_num_patents"
)
# We'll post to the API, the query is a pretty large string (an "or" of 75 assignee_ids)
assignee_out <- search_pv(assignee_query , fields = assignee_fields, all_pages = TRUE,
size = 1000, endpoint = "assignee", method = "POST")
assignee_counts <- unnest_pv_data(assignee_out$data, "assignee_id")
assignee_counts
#> List of 1
#> $ assignees:'data.frame': 75 obs. of 3 variables:
#> ..$ assignee_id : chr [1:75] "039fd1f0-2b7d-4640-a6ff-073778f2f50b"..
#> ..$ assignee_organization: chr [1:75] "Digital Global Systems, Inc." ...
#> ..$ assignee_num_patents : int [1:75] 396 566 ...
# Here we redo top_asgns now that we have all the fields we need.
# We join in the total counts and mutate in the percentages
top_asgns <- dl$assignees %>%
inner_join(assignee_counts$assignees) %>%
rename(ttl_pats = assignee_num_patents) %>%
group_by(assignee_organization, ttl_pats) %>%
summarise(db_pats = n()) %>%
mutate(frac_db_pats = round(db_pats / ttl_pats, 3)) %>%
select(c(1, 3, 2, 4)) %>%
arrange(desc(db_pats))
# trying to avoid Error: Chromote: timed out waiting for event Page.loadEventFired
knitr::opts_chunk$set(
delay = 45
)
# Create datatable
datatable(
data = top_asgns,
rownames = FALSE,
colnames = c(
"Assignee", "DB patents", "Total patents", "DB patents / total patents"
),
caption = htmltools::tags$caption(
style = 'caption-side: top; text-align: left; font-style: italic;',
"Table 1: Top assignees in 'databases'"
),
options = list(pageLength = 10)
)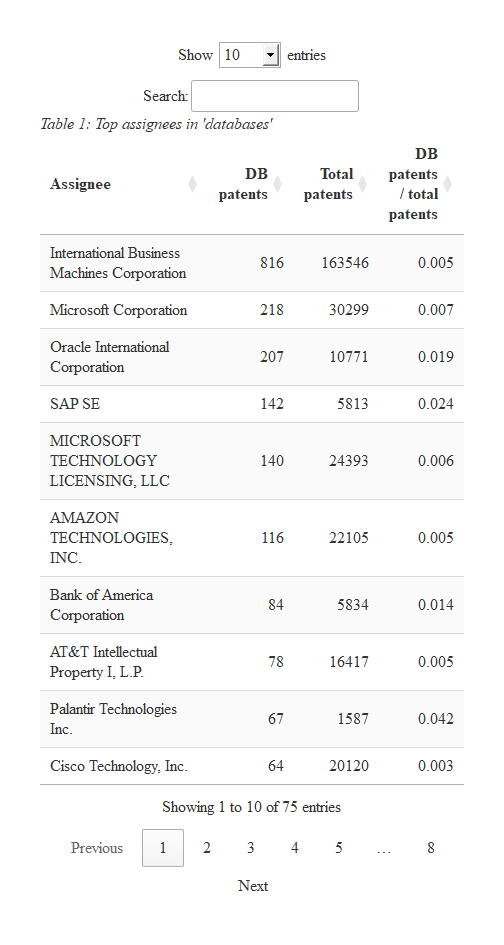
IBM is far and away the biggest player in the field. However, we can see that Oracle and Salesforce.com are relatively more interested in this area, as indicated by the fraction of their patents that relate to databases.
- Let’s see how these assignees’ level of investment in databases has changed over time.
# Comment from the original version of this page:
# Create a data frame with patent counts by application year for each assignee
# The patent endpoint can now return "patent_earliest_application_date" and/or
# application.filing_date. We requested both above so we can use either here
# to create app_yr. The API's data dictionary (if one exists) would need to be
# consulted to find out how these fields differ. (There are data dictionaries for
# the bulk downloadable files, I'll follow up with the API team to see if there
# is one for the API.)
# We'll use patent_earliest_application_date, we'd need an additional
# full_join(., dl$application) %>% if we want to use filing_date
# mutate(app_yr = as.numeric(substr(filing_date, 1, 4)))
# As an aside, I don't think it's possible to querry the API for patents
# where the two fields differ, least not directly. We could request both
# fields and look for differences ourselves but we can't query where
# {"_neq":{"patent_earliest_application_date":{"application.filing_date"}}
# Get the top 5 organizations since slice wasn't working out in the full_join below.
# We want data to just be the top 5 assignees, not all 75 assignees
top_five <- head(top_asgns, n = 5)
data <-
full_join(dl$assignees, dl$patents) %>%
mutate(app_yr = as.numeric(substr(patent_earliest_application_date, 1, 4))) %>%
group_by(assignee_organization, app_yr) %>%
summarise(n = n()) %>%
inner_join(top_five) %>%
select(assignee_organization, app_yr, n)
# Plot the data using highcharter:
hchart(
data, "line",
hcaes(x = app_yr, y = n, group = assignee_organization)
) %>%
hc_plotOptions(series = list(marker = list(enabled = FALSE))) %>%
hc_xAxis(title = list(text = "Grant year")) %>%
hc_yAxis(title = list(text = "Patents")) %>%
hc_title(text = "Top five assignees in 'databases'") %>%
hc_subtitle(text = "Yearly patent applications over time")
It’s hard to see any clear trends in this graph. What is clear is that the top assignees have all been patenting in the field for many years.
- Finally, let’s see how the organizations compare in terms of their citation rates. First, we’ll need to normalize the raw citation counts by publication year, so that older patents don’t have an unfair advantage over younger patents (i.e., because they have had a longer time to accumulate citations).
# Write a ranking function that will be used to rank patents by their citation counts
percent_rank2 <- function(x)
(rank(x, ties.method = "average", na.last = "keep") - 1) / (sum(!is.na(x)) - 1)
# Create a data frame with normalized citation rates and stats from Step 2
asng_p_dat <-
dl$patents %>%
# mutate(patent_yr = substr(patent_date, 1, 4)) %>%
group_by(patent_year) %>%
mutate(perc_cite = percent_rank2(patent_num_us_patents_cited)) %>%
inner_join(dl$assignees) %>%
group_by(assignee_organization) %>%
summarise(mean_perc = mean(perc_cite)) %>%
inner_join(top_asgns) %>%
arrange(desc(ttl_pats)) %>%
slice(1:20) %>%
mutate(color = "#f1c40f") %>%
as.data.frame()
kable(head(asng_p_dat), row.names = FALSE)| assignee_organization | mean_perc | db_pats | ttl_pats | frac_db_pats | color |
|---|---|---|---|---|---|
| International Business Machines Corporation | 0.4678589 | 816 | 163546 | 0.005 | #f1c40f |
| SONY GROUP CORPORATION | 0.3564428 | 29 | 62652 | 0.000 | #f1c40f |
| FUJITSU LIMITED | 0.4034433 | 45 | 56293 | 0.001 | #f1c40f |
| Intel Corporation | 0.3462831 | 20 | 52745 | 0.000 | #f1c40f |
| General Electric Company | 0.4491179 | 24 | 51898 | 0.000 | #f1c40f |
| HITACHI, LTD. | 0.3609991 | 50 | 46007 | 0.001 | #f1c40f |
Now let’s visualize the data. Each assignee will be represented by a point/bubble. The x-value of the point will represent the total number of patents the assignee has published in the field of databases (on a log scale), while the y-value will represent its average normalized citation rate. The size of the bubble will be proportional to the percent of the assignee’s patents that relate to databases.
# Adapted from https://jkunst.com/highcharter/articles/showcase.html
hchart(
asng_p_dat, "scatter",
hcaes(x = db_pats, y = mean_perc, size = frac_db_pats,
group = assignee_organization, color = color)
) %>%
hc_xAxis(
title = list(text = "DB patents"), type = "logarithmic",
allowDecimals = FALSE, endOnTick = TRUE
) %>%
hc_yAxis(title = list(text = "Mean cite perc.")) %>%
hc_title(text = "Top assignees in 'databases'") %>%
hc_add_theme(hc_theme_flatdark()) %>%
hc_tooltip(
useHTML = TRUE, pointFormat = tooltip_table(
x = c("DB patents", "Mean cite percentile", "Fraction DB patents"),
y = c("{point.db_pats:.0f}","{point.mean_perc:.2f}", "{point.frac_db_pats:.3f}")
)) %>%
hc_legend(enabled = FALSE)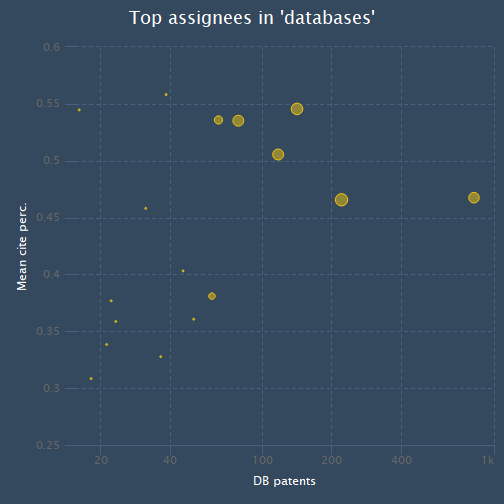
It looks like Microsoft has relatively high values across all three three metrics (average citation percentile, number of database patents, and percent of total patents that are related to databases). IBM has more patents than Microsoft, but also has a lower average citation percentile.