Following the template in OpenAlex’s oa-percentage tutorial, this vignette uses openalexR to answer:
How many of recent journal articles from the University of Pennsylvania are open access? And how many aren’t?
We first need to find the openalex.id for
University of Pennsylvania. We can do this by fetching for the
institutions entity and put “University of
Pennsylvania” in display_name or
display_name.search:
oa_fetch(
entity = "inst", # same as "institutions"
display_name.search = "\"University of Pennsylvania\""
) %>%
select(display_name, ror) %>%
knitr::kable()| display_name | ror |
|---|---|
| University of Pennsylvania | https://ror.org/00b30xv10 |
| California University of Pennsylvania | https://ror.org/01spssf70 |
| Hospital of the University of Pennsylvania | https://ror.org/02917wp91 |
| University of Pennsylvania Health System | https://ror.org/04h81rw26 |
| Indiana University of Pennsylvania | https://ror.org/0511cmw96 |
| University of Pennsylvania Press | https://ror.org/03xwa9562 |
| Cheyney University of Pennsylvania | https://ror.org/02nckwn80 |
We will use the first ror, 00b30xv10, as one of the filters for our query.
Alternatively, we could go to the autocomplete endpoint at https://explore.openalex.org/ to search for “University of Pennsylvania” and find the ror there!
All other filters are straightforward and explained in detail in the
original jupyter notebook tutorial.
The only difference here is that, instead of grouping by
is_oa, we’re interested in the “trend” over the years, so
we’re going to group by publication_year, and perform the
query twice, one for is_oa = "true" and one for
is_oa = "false" .
open_access <- oa_fetch(
entity = "works",
institutions.ror = "00b30xv10",
type = "article",
from_publication_date = "2012-08-24",
is_paratext = "false",
is_oa = "true",
group_by = "publication_year"
)
closed_access <- oa_fetch(
entity = "works",
institutions.ror = "00b30xv10",
type = "article",
from_publication_date = "2012-08-24",
is_paratext = "false",
is_oa = "false",
group_by = "publication_year"
)
uf_df <- closed_access %>%
select(- key_display_name) %>%
full_join(open_access, by = "key", suffix = c("_ca", "_oa"))
uf_df
#> key count_ca key_display_name count_oa
#> 1 2018 4497 2018 5831
#> 2 2015 4386 2015 4976
#> 3 2014 4325 2014 4816
#> 4 2013 4294 2013 4623
#> 5 2022 4238 2022 7786
#> 6 2019 4204 2019 6647
#> 7 2020 4170 2020 8275
#> 8 2021 4072 2021 8349
#> 9 2016 4021 2016 5147
#> 10 2017 3977 2017 5364
#> 11 2025 3938 2025 8447
#> 12 2024 3846 2024 8478
#> 13 2023 3484 2023 8665
#> 14 2026 2618 2026 3866
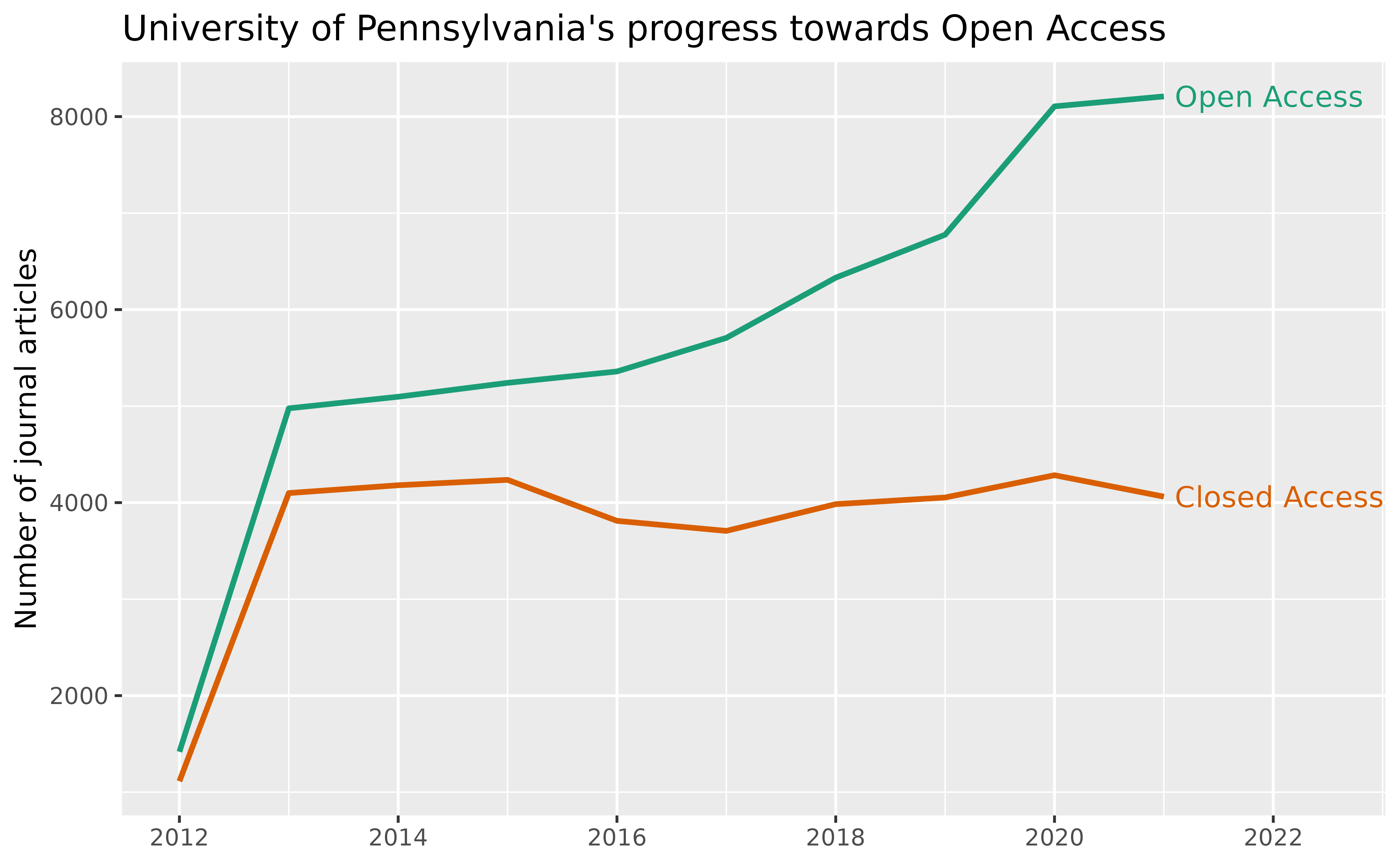
#> 15 2012 1353 2012 1143Finally, we compare the number of open vs. closed access articles over the years:
uf_df %>%
filter(key <= 2021) %>% # we do not yet have complete data for 2022 and after
pivot_longer(cols = starts_with("count")) %>%
mutate(
year = as.integer(key),
is_oa = recode(
name,
"count_ca" = "Closed Access",
"count_oa" = "Open Access"
),
label = if_else(key < 2021, NA_character_, is_oa)
) %>%
select(year, value, is_oa, label) %>%
ggplot(aes(x = year, y = value, group = is_oa, color = is_oa)) +
geom_line(size = 1) +
labs(
title = "University of Pennsylvania's progress towards Open Access",
x = NULL, y = "Number of journal articles") +
scale_color_brewer(palette = "Dark2", direction = -1) +
scale_x_continuous(breaks = seq(2010, 2024, 2)) +
geom_text(aes(label = label), nudge_x = 0.1, hjust = 0) +
coord_cartesian(xlim = c(NA, 2022.5)) +
guides(color = "none")