Introduction
Sometimes, a large dataframe has one or more variables with a small number of unique combinations. E.g. a dataframe with one or more factor variables. Storing the entire dataframe as a single text file requires storing lots of replicated data. Each row stores the information for every variable, even if a subset of these variables remains constant over a subset of the data.
In such a case we can use the split_by argument of
write_vc(). This will store the large dataframe over a set
of tab separated files. One file for every combination of the variables
defined by split_by. Every partial data file holds the
other variables for one combination of split_by. We remove
the split_by variables from the partial data files,
reducing their size. We add an index.tsv containing the
combinations of the split_by variables and a unique hash
for each combination. This hash becomes the base name of the partial
data files.
Splitting the dataframe into smaller files makes them easier to handle in version control system. The total size depends on the amount of replication in the dataframe. More on that in the next section.
When to Split the Dataframe
Let’s set the following variables:
: the average number of bytes to store a single line of the
split_byvariables.: the average number of bytes to store a single line of the remaining variables.
: the number of bytes to store the header of the
split_byvariables.: the number of bytes to store the header of the remaining variables.
: the number of rows in the dataframe.
: the number of unique combinations of the
split_byvariables.
Storing the dataframe with write_vc() without
split_by requires
bytes for the header and
bytes for every observation. The total number of bytes is
.
Both
originate from the tab character to separate the split_by
variables from the remaining variables.
Storing the dataframe with write_vc() with
split_by requires an index file to store the combinations
of the split_by variables. It will use
bytes for the header and
for the data. The headers of the partial data files require
bytes
(
files and
byte per file). The data in the partial data files require
bytes. The total number of bytes is
.
We can look at the ratio of over .
Let’s simplify the equation by assuming that we need an equal amount of character for the headers and the data ( and ).
Let assume that with and with .
When is large, we can state that and .
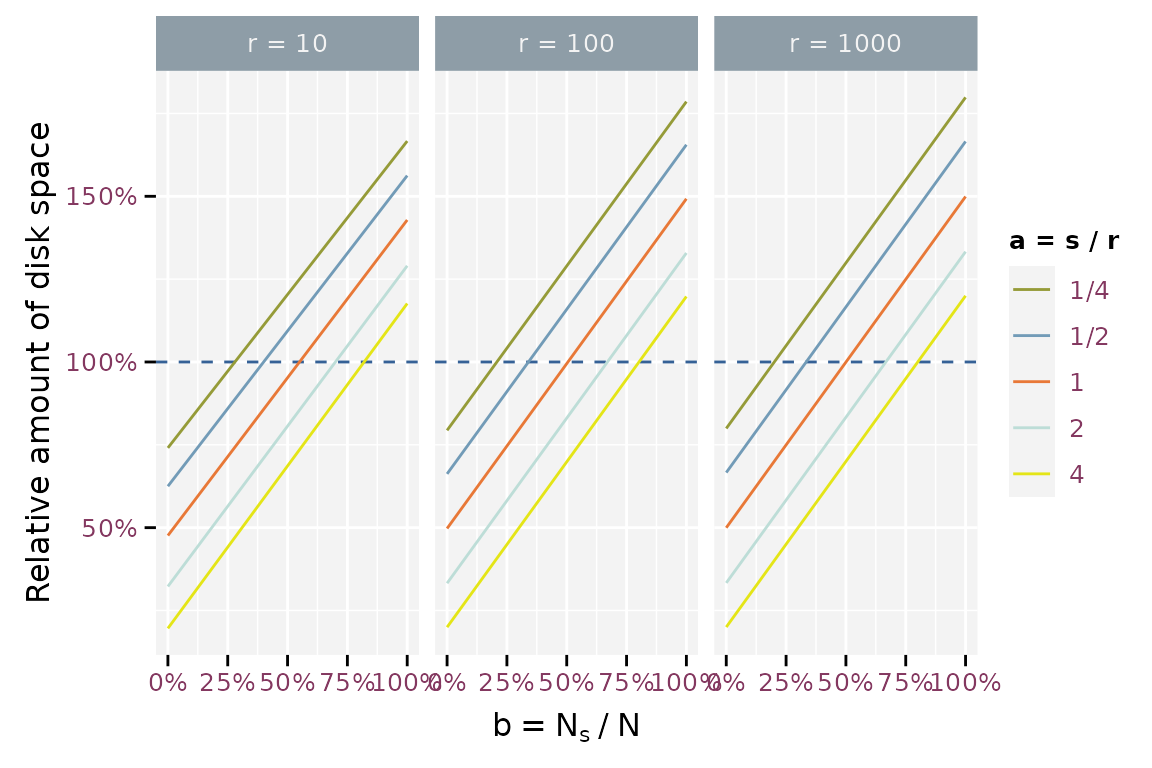
Storage space required using split_by relative to storing a
single file.
The figure illustrates that using split_by is more
efficient when the number of unique combinations
()
of the split_by variables is much smaller than the number
of rows in the dataframe
().
The efficiency also increases when the storage for a single combination
of split_by variables
()
is larger than the storage needed for a single line of the remain
variables
().
The storage needed for a single line of the remain variables
()
doesn’t influence the efficiency.
Benchmarking
library(git2rdata)
root <- tempfile("git2rdata-split-by")
dir.create(root)
library(microbenchmark)
mb <- microbenchmark(
part_1 = write_vc(airbag, "part_1", root, sorting = "X"),
part_2 = write_vc(airbag, "part_2", root, sorting = "X", split_by = "airbag"),
part_3 = write_vc(airbag, "part_3", root, sorting = "X", split_by = "abcat"),
part_4 = write_vc(
airbag, "part_4", root, sorting = "X", split_by = c("airbag", "sex")
),
part_5 = write_vc(airbag, "part_5", root, sorting = "X", split_by = "dvcat"),
part_6 = write_vc(
airbag, "part_6", root, sorting = "X", split_by = "yearacc"
),
part_15 = write_vc(
airbag, "part_15", root, sorting = "X", split_by = c("dvcat", "abcat")
),
part_45 = write_vc(
airbag, "part_45", root, sorting = "X", split_by = "yearVeh"
),
part_270 = write_vc(
airbag, "part_270", root, sorting = "X", split_by = c("yearacc", "yearVeh")
)
)
mb$time <- mb$time / 1e6Splitting the dataframe over more than one file takes more time to write the data. The log time seems to increase quadratic with log number of parts.
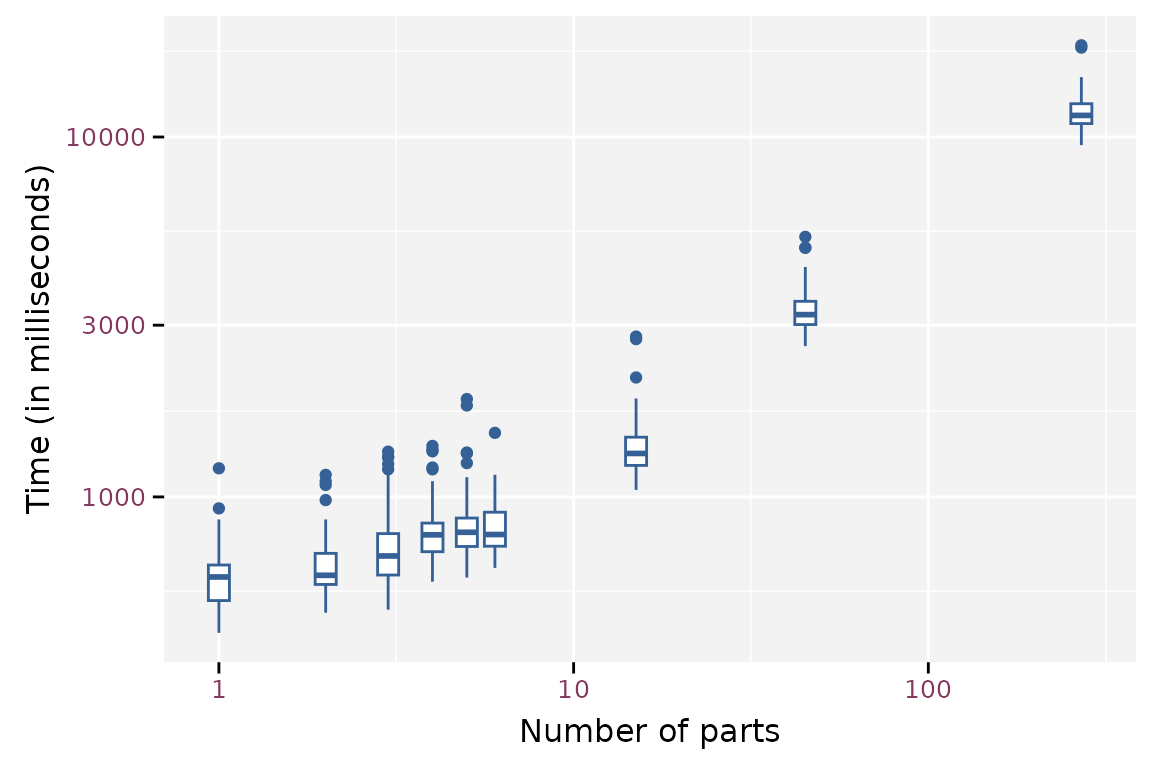
Boxplot of the write timings for different number of parts.
mb_r <- microbenchmark(
part_1 = read_vc("part_1", root),
part_2 = read_vc("part_2", root),
part_3 = read_vc("part_3", root),
part_4 = read_vc("part_4", root),
part_5 = read_vc("part_5", root),
part_6 = read_vc("part_6", root),
part_15 = read_vc("part_15", root),
part_45 = read_vc("part_45", root),
part_270 = read_vc("part_270", root)
)
mb_r$time <- mb_r$time / 1e6A small number of parts does not seem to affect the read timings much. Above ten parts, the required time for reading seems to increase. The log time seems to increase quadratic with log number of parts.
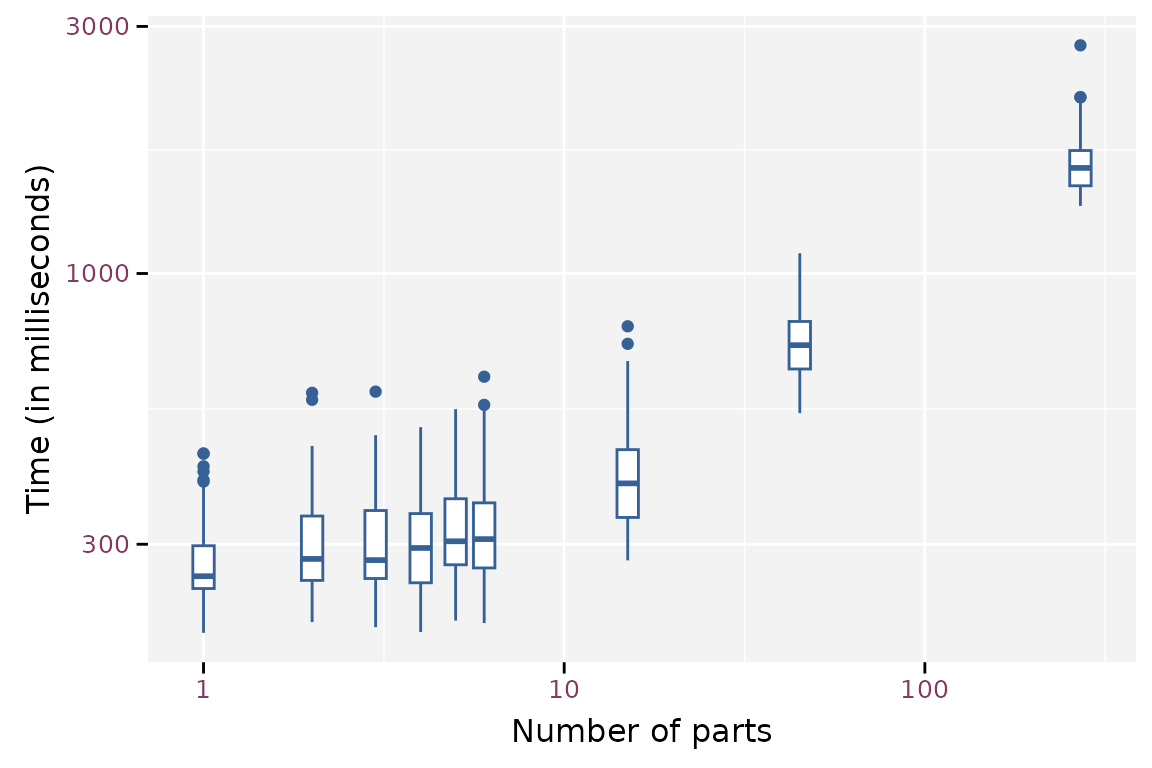
Boxplot of the read timings for the different number of parts.