Getting started with `plater`
Sean Hughes
2026-07-01
Source:vignettes/plater-basics.Rmd
plater-basics.RmdHow plater helps you
plater makes it easy to work with data from experiments
performed in plates.
Many scientific instruments (such as plate readers and qPCR machines)
produce data in tabular form that mimics a microtiter plate: each cell
corresponds to a well as physically laid out on the plate. For
experiments like this, it’s often easiest to keep records of what was
what (control vs. treatment, concentration, sample type, etc.) in a
similar plate layout form. But while plate-shaped data is easy to think
about, it’s not easy to analyze. The point of plater is to
seamlessly convert plate-shaped data (easy to think about) into tidy
data (easy to analyze). It does this by defining a simple, systematic
format for storing information in plate layouts. Then it painlessly
rearranges data that intuitive format into a tidy data frame.
There are just two steps:
- Put the data in a file in
platerformat - Read in the data
platerfunctions
The example
Imagine you’ve invented two new antibiotics. To show how well they work, you filled up a 96-well plate with dilutions of the antibiotics and mixed in four different types of bacteria. Then, you measured how many of the bacteria got killed. So for each well in the plate you know:
- The drug (A or B)
- The concentration of drug (100 uM to 0.01 nM and no drug)
- The bacterial species (E. coli, S. enterocolitis, C. trachomatis, and N. gonorrhoeae)
- The amount of killing in the well
The first three items are variables you chose in setting up the experiment. The fourth item is what you measured.
Step 1: Put the data in plater format
The first step is to create a file for the experiment.
plater format is designed to store all the information
about an experiment in one file. It’s simply a .csv file representing a
single plate, containing one or more plate layouts. Each layout maps to
a variable, so for the example experiment, there are four layouts in the
file: Drug, Concentration, Bacteria, and Killing.
A plater format file for the example experiment came
with the package. Load plater (i.e. run
library(plater)) and then run
system.file("extdata", package = "plater"). Open the folder
listed there and then open example-1.csv in a spreadsheet
editor.
An abbreviated version of that file is shown below:
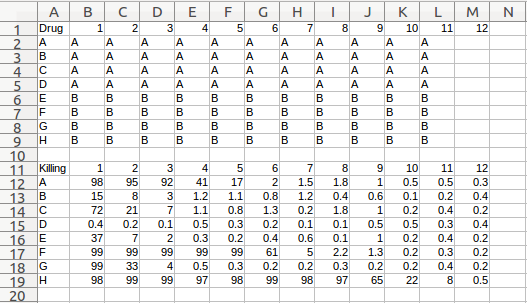
The format is pretty simple:
- .csv file
- Top left cell of each layout is the name
- The rest of the top row of each layout is the column numbers (1:12 for a 96-well plate)
- The rest of the left column is the row names (A:H for a 96-well plate)
- One line between layouts (This row should appear as blank in a spreadsheet editor, but as a row of commas when viewed as plain text.)
You can use plater format with any standard plate size
(6 to 1536 wells). Not every well has to be filled. If a well is blank
in every layout in a file, it’s omitted. If it’s blank in some but not
others, it’ll get NA where it’s blank.
While creating a file in plater format, it can be
helpful to check whether you’re doing it right. For that purpose, you
can pass the path of the file to check_plater_format(),
which will check that the format is correct and diagnose any
problems.
Step 2: Read in the data
Now that your file is set up, you’re ready to read in the data.
We will analyze this experiment two different ways to illustrate two common data analysis scenarios:
- Assuming the instrument gives back the killing data shaped like a
plate, we’ll create one file with all four variables and read it in with
read_plate(). - Assuming the instrument gives back tidy data (one-well-per-row),
we’ll create two files–one with the data and one with the three
variables–and then combine the files with
add_plate().
Step 2: Read a single plater format file with
read_plate()
Here is how it works. (Note that below we use
system.file() here to get the file path of the example
file, but for your own files you would specify the file path without
using system.file()).
file_path <- system.file("extdata", "example-1.csv", package = "plater")
data <- read_plate(
file = file_path, # full path to the .csv file
well_ids_column = "Wells", # name to give column of well IDs (optional)
sep = "," # separator used in the csv file (optional)
)
str(data)
#> Classes 'tbl_df', 'tbl' and 'data.frame': 96 obs. of 5 variables:
#> $ Wells : chr "A01" "A02" "A03" "A04" ...
#> $ Drug : chr "A" "A" "A" "A" ...
#> $ Concentration: num 1.00e+02 2.00e+01 4.00 8.00e-01 1.60e-01 3.20e-02 6.40e-03 1.28e-03 2.56e-04 5.12e-05 ...
#> $ Bacteria : chr "E. coli" "E. coli" "E. coli" "E. coli" ...
#> $ Killing : num 98 95 92 41 17 2 1.5 1.8 1 0.5 ...
head(data)
#> Wells Drug Concentration Bacteria Killing
#> 1 A01 A 100.000 E. coli 98
#> 2 A02 A 20.000 E. coli 95
#> 3 A03 A 4.000 E. coli 92
#> 4 A04 A 0.800 E. coli 41
#> 5 A05 A 0.160 E. coli 17
#> 6 A06 A 0.032 E. coli 2So what happened? read_plate() read in the
plater format file you created and turned each layout into
a column, using the name of the layout specified in the file. So you
have four columns: Drug, Concentration, Bacteria, and Killing. It
additionally creates a column named “Wells” with the well identifiers
for each well. Now, each well is represented by a single row, with the
values indicated in the file for each column.
Step 2 (again): Combine a one-well-per-row file and a
plater format file with add_plate()
In the previous example, we assumed that the killing data was
provided by the instrument in plate-shaped form, so it could just be
pasted into the plater format file. Sometimes, though,
you’ll get data back formatted with one well per row.
add_plate() is set up to help in this situation. You
provide a tidy data frame including well IDs and then you provide a
plater format file with the other information and
add_plate() knits them together well-by-well. Here’s an
example using the other two files installed along with
plater.
file2A <- system.file("extdata", "example-2-part-A.csv", package = "plater")
data2 <- read.csv(file2A)
str(data2)
#> 'data.frame': 96 obs. of 2 variables:
#> $ Wells : chr "A01" "A02" "A03" "A04" ...
#> $ Killing: num 98 95 92 41 17 2 1.5 1.8 1 0.5 ...
head(data2)
#> Wells Killing
#> 1 A01 98
#> 2 A02 95
#> 3 A03 92
#> 4 A04 41
#> 5 A05 17
#> 6 A06 2
meta <- system.file("extdata", "example-2-part-B.csv", package = "plater")
data2 <- add_plate(
data = data2, # data frame to add to
file = meta, # full path to the .csv file
well_ids_column = "Wells", # name of column of well IDs in data frame
sep = "," # separator used in the csv file (optional)
)
str(data2)
#> tibble [96 × 5] (S3: tbl_df/tbl/data.frame)
#> $ Wells : chr [1:96] "A01" "A02" "A03" "A04" ...
#> $ Killing : num [1:96] 98 95 92 41 17 2 1.5 1.8 1 0.5 ...
#> $ Drug : chr [1:96] "A" "A" "A" "A" ...
#> $ Concentration: num [1:96] 1.00e+02 2.00e+01 4.00 8.00e-01 1.60e-01 3.20e-02 6.40e-03 1.28e-03 2.56e-04 5.12e-05 ...
#> $ Bacteria : chr [1:96] "E. coli" "E. coli" "E. coli" "E. coli" ...
head(data2)
#> # A tibble: 6 × 5
#> Wells Killing Drug Concentration Bacteria
#> <chr> <dbl> <chr> <dbl> <chr>
#> 1 A01 98 A 100 E. coli
#> 2 A02 95 A 20 E. coli
#> 3 A03 92 A 4 E. coli
#> 4 A04 41 A 0.8 E. coli
#> 5 A05 17 A 0.16 E. coli
#> 6 A06 2 A 0.032 E. coliadd_plate then makes it easy to store data in a mix of
formats, in some cases tidy and in some cases plate-shaped, which is the
reality of many experiments.
Multiple plates
Say you were happy with the tests of you antibiotics, so you decided
to do a second experiment, testing some other common pathogenic
bacteria. Now you have data from two separate plates. Rather than
handling them separately, you can combine them all into a common data
frame with the read_plates() function.
Just like before, you create one plater file per plate,
with all the information describing the experiment. In this case, you’ll
have two files, one from each experiment. Then, just read them in with
read_plates(). You can specify names for each plate, which
will become a column in the output identifying which plate the well was
on. By default it’ll use the file names.
# same file as above
file1 <- system.file("extdata", "example-1.csv", package = "plater")
# new file
file2 <- system.file("extdata", "more-bacteria.csv", package = "plater")
data <- read_plates(
files = c(file1, file2),
plate_names = c("Experiment 1", "Experiment 2"),
well_ids_column = "Wells", # optional
sep = ",") # optional
str(data)
#> tibble [192 × 6] (S3: tbl_df/tbl/data.frame)
#> $ Plate : chr [1:192] "Experiment 1" "Experiment 1" "Experiment 1" "Experiment 1" ...
#> $ Wells : chr [1:192] "A01" "A02" "A03" "A04" ...
#> $ Drug : chr [1:192] "A" "A" "A" "A" ...
#> $ Concentration: num [1:192] 1.00e+02 2.00e+01 4.00 8.00e-01 1.60e-01 3.20e-02 6.40e-03 1.28e-03 2.56e-04 5.12e-05 ...
#> $ Bacteria : chr [1:192] "E. coli" "E. coli" "E. coli" "E. coli" ...
#> $ Killing : num [1:192] 98 95 92 41 17 2 1.5 1.8 1 0.5 ...
head(data)
#> # A tibble: 6 × 6
#> Plate Wells Drug Concentration Bacteria Killing
#> <chr> <chr> <chr> <dbl> <chr> <dbl>
#> 1 Experiment 1 A01 A 100 E. coli 98
#> 2 Experiment 1 A02 A 20 E. coli 95
#> 3 Experiment 1 A03 A 4 E. coli 92
#> 4 Experiment 1 A04 A 0.8 E. coli 41
#> 5 Experiment 1 A05 A 0.16 E. coli 17
#> 6 Experiment 1 A06 A 0.032 E. coli 2Viewing plate-shaped data
Sometimes it’s useful to look back at the data in plate shape. Was there something weird about that one column? Was there contamination all in one corner of the plate?
For this, use view_plate() which takes a tidy data frame
and displays columns from it as plate layouts.
view_plate(
data = data2,
well_ids_column = "Wells",
columns_to_display = c("Concentration", "Killing")
)
#> $Concentration
#> 1 2 3 4 5 6 7 8 9 10 11 12
#> A 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#> B 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#> C 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#> D 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#> E 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#> F 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#> G 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#> H 100 20 4 0.8 0.16 0.032 0.0064 0.00128 0.000256 5.12e-05 1.024e-05 0
#>
#> $Killing
#> 1 2 3 4 5 6 7 8 9 10 11 12
#> A 98 95 92 41 17 2 1.5 1.8 1 0.5 0.5 0.3
#> B 15 8 3 1.2 1.1 0.8 1.2 0.4 0.6 0.1 0.2 0.4
#> C 72 21 7 1.1 0.8 1.3 0.2 1.8 1 0.2 0.4 0.2
#> D 0.4 0.2 0.1 0.5 0.3 0.2 0.1 0.1 0.5 0.5 0.3 0.4
#> E 37 7 2 0.3 0.2 0.4 0.6 0.1 1 0.2 0.4 0.2
#> F 99 99 99 99 99 61 5 2.2 1.3 0.2 0.3 0.2
#> G 99 33 4 0.5 0.3 0.2 0.2 0.3 0.2 0.2 0.4 0.2
#> H 98 99 99 97 98 99 98 97 65 22 8 0.5