refsplitr
Auriel M. V. Fournier, Matthew E. Boone, Forrest R. Stevens, Emilio M. Bruna
2025-03-25
Source:vignettes/refsplitr.Rmd
refsplitr.Rmd1. Introduction
The Science of Science (SciSci) is an emerging, trans-disciplinary approach for using large and disparate data-sets to study the emergence, dissemination, and impact of scientific research (Fortunato et al. 2018). Bibliometric databases such as the Web of Science are rich sources of data for SciSci studies (Sugimoto and Larivière 2018). In recent years the type and scope of questions addressed with data gathered from these databases has expanded tremendously (Forutnato et al. 2018). This is due in part to their expanding coverage and greater accessibility, but also because advances in computational power make it possible to analyze data-sets comprising millions of bibliographic records (e.g., Larivière et al. 2013, Smith et al. 2014).
The rapidly increasing size of bibliometric data-sets available to researchers has exacerbated two major and persistent challenges in SciSci research. The first of these is Author Name Disambiguation. Correctly identifying the authors of a research product is fundamental to bibliometric research, as is the ability to correctly attribute to a given author all of their scholarly output. However, this seemingly straightforward task is often extremely complicated, even when using the nominally high-quality data extracted from bibliometric databases (reviewed in Smalheiser and Torvik 2009). The most obvious case is when different authors have identical names, which can be quite common in some countries (Strotmann et al. 2009). However, confusion might also arise as a result of journal conventions or individual preferences for abbreviating names. For instance, one might conclude “J. C. Smith”, “Jennifer C. Smith”, and “J. Smith” are different authors, when in fact they are the same person. In contrast, papers by “E. Martinez” could have been written by different authors with the same last name but whose first names start with the same letter (e.g., “Enrique”, “Eduardo”). Failure to disambiguate author names can seriously undermine the conclusions of some SciSci studies, but manually verifying author identity quickly becomes impractical as the number of authors or papers in a dataset increases.
The second challenge to working with large bibliometric data-sets is correctly parsing author addresses. The structure of author affiliations is complex and idiosyncratic, and journals differ in the information they require authors to provide and the way in which they present it. Authors may also represent affiliations in different ways on different articles. For instance, the affiliations might be written in different ways in different journals (e.g., “Dept. of Biology”, “Department of Biology”, “Departamento de Biologia”). The same is true of the institution’s name (“UC Davis”, “University of California-Davis”,“University of California”) or the country in which it is based (“USA”, “United States”, “United States of America”). Researchers at academic institutions might include the one or more Centers, Institutes, Colleges, Departments, or Programs in their address, and researchers working for the same institution could be based at units in geographically disparate locations (e.g., University of Florida researchers could be based at the main campus in Gainesville or one of dozens of facilities across the state, including 12 Research and Education Centers, 5 field stations, and 67 County Extension Offices). Finally, affiliations are recorded in a single field of a reference’s bibliographic record, despite comprising very different types of information (e.g., city, postal code, institution). In concert, these factors can make it challenging to conduct analyses for which author affiliation or location is of particular interest.
Package refsplitr
helps users of the R statistical computing environment (R Core Team
2017) address these challenges. It imports and organizes the output from
Web of Science searches, disambiguates author names and suggests which
might need additional scrutiny, parses author addresses, and
georeferences authors’ institutions. It also maps author locations and
coauthorship networks. Finally, the processed data-sets can be exported
in tidy formats for analysis with user-written code or, after some
additional formatting, packages such as revtools
(Westgate 2018) or bibliometrix
(Aria & Cuccurullo 2017).
2. Using refsplitr
Appendix 1 provides guidance on downloading records from the Web of
Science in the proper format for use in refsplitr. Once
bibliographic records have been downloaded, the refsplitr
package’s tools are applied in four steps:
- Importing and tidying reference records (Section 2.1)
- Author name disambiguation and parsing of author addresses (Section 2.2)
- Georeferencing of author institutions (Section 2.3)
- Data visualization (Section 2.4)
Learning to use refspliter with the examples
below: The examples below use the dataset ‘example_data.txt’
included with the refsplitr package. To use them, (1)
create two folders in the working directory or Rstudio project: one
named “data”, and one named “output”. (2) Save the sample data
‘example_data.txt’ file in the ‘data’ folder. This is the same folder
structure we recommend for saving and processing your own WOS output
files.
2.1. Importing Search Results
The refsplitr package can either import a single Web of
Science search result file or combine and import multiple files located
in the same directory. The acceptable file formats are ‘.txt’ and ‘.ciw’
(Appendix 1). Importing reference records is done with the
references_read() function, which has three arguments:
data: The location of the directory in which the Web of Science file(s) are located. If left blank it assumes the files are in the working directory. If in a different directory (e.g., the ‘data’ folder in the working directory), the absolute file name or relative file paths can be used.
dir: when loading a single file dir=FALSE, when loading multiple files dir=TRUE. If multiple files are processed
refsplitrwill identify and remove any duplicate reference records.include_all: Setting ‘include_all=TRUE’ will import all fields from the WOS record (see Appendix 2). The default is ‘include_all=FALSE’.
The output of references_read() is an object in the R
workspace. Each line of the output is a reference; the columns are the
name of the .txt file from which the data were extracted, a unique id
number assigned by refsplitr to each article, and the data
from each field of the reference record (see Appendix 2 for a list of
these data fields and their Web
of Science and RIS codes). This object is used by
refsplitr in Step 2.2; we recommend also saving it as a
.csv file in the “output” folder.
Example
- To import and process a single file, set dir=FALSE and set data equal to the file path. For example, if the file “example_data.txt” were saved in the “data” folder of the RStudio project, you would import and process the data file as follows:
example_refs <- references_read(data = "./data/example_data.txt",
dir=FALSE,
include_all = FALSE)- To import and process multiple files, set “dir = TRUE” and use “data=” to indicate the folder containing the files. For instance, if the files were saved in a folder called “UF_data” inside the “data” folder of the RStudio project, they would be imported and processed as follows:
example_refs <- references_read(data = "./data/UF_data",
dir=TRUE,
include_all = FALSE)- The sample data used in the examples below can be loaded and processed as follows:
example_refs <- references_read(data = system.file("extdata",package = "refsplitr"),
dir = TRUE,
include_all = FALSE)- The processed references can then be saved as a .csv file in the “output” folder of the RStudio project:
write.csv(example_refs,"./output/example_refs.csv")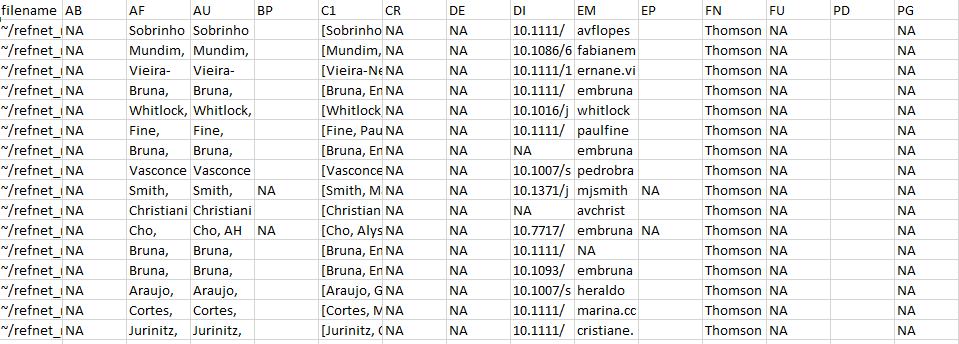
plot of chunk unnamed-chunk-24
Figure 1 An image of the .csv file showing a subset
of the rows and columns from the output of
references_read().
2.2. Author address parsing and name disambiguation
The next step is to identify all unique authors in the dataset and
parse their affiliations for each of their articles. This requires
identifying any authors whose name appears to be represented in
different ways on different publications. Name disambiguation is a
complex statistical and computational problem for which researchers have
used data ranging from author affiliation to patterns of coauthorship
and citation (reviewed in Smalheiser & Torvik 2009). The
authors_clean() disambiguation algorithm is described in
detail in Appendix 4. Briefly, it first assigns every author of every
article in the dataset a unique identification number (“authorID”). It
then uses the information provided about the authors of each article
(e.g., email addresses, ORCID numbers) to putatively pool all names and
name variants representing the same author in a group. The groups of
names/name variants representing different authors are then each
assigned a unique identification number (i.e., the different “authorID”
numbers putatively determined to be the same author are assigned the
same “groupID” number). The function authors_clean() has
one argument:
-
references: The object created by
references_read(), from which author names will be extracted. Any previously generated output fromreferences_read()that has been saved to an object can be used.
The output of authors_clean() is a list in the R
workspace with two elements: (1) “prelim”, which is the preliminary list
of disambiguated author names, and (2) “review”, which is the subset of
authors with putative name variants suggested for verification. Each of
these elements can be saved as a separate .csv file; the examples below
assume they have been saved in the “output” folder.
Once disambiguation is complete, users can accept
refsplitr‘s preliminary results and generate the ’refined’
dataset used for analyses (Section 2.2.1). Alternatively, users can
inspect the subset of names recommended by by refsplitr for
review, make any corrections necessary (Section 2.2.2), and upload the
corrections to create the ‘refined’ dataset (Section 2.2.3).
Example
- To disambiguate the authors of the references in the dataset:
example_a_clean <- authors_clean(example_refs)- To save the resulting list elements – ‘prelim’ and ‘review’ – in the “output” folder of the RStudio project as .csv files:
write.csv(example_a_clean$prelim,"./output/example_a_clean_prelim.csv")
write.csv(example_a_clean$review,"./output/example_a_clean_review.csv")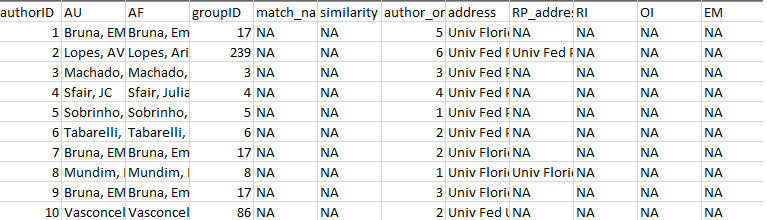
plot of chunk unnamed-chunk-27
Figure 2 A subset of the .csv file showing the rows
and columns in the ‘prelim’ output from
authors_clean().
2.2.1. Accepting the results of author disambiguation without manual review
Accepting the result of refsplitr’s disambiguation
algorithm without inspecting names flagged for review is done with the
authors_refine() function. It has four arguments:
review: The names proposed for manual review by
authors_clean(). Must be in an object.prelim: The preliminary file of disambiguated author names created with
authors_clean(). Must be an object.sim_score: The threshold for the similarity score below which authors are assigned different groupIDs. The range of sim_score is 0-1 (1 = names must be identical to be assigned to the same group). This argument is optional, if not included the function will use a default sim_score = 0.9.
confidence: The threshold for the confidence score below which authors are assigned different groupIDs. The range of ‘confidence’ is 0-10 (0 = the name and matched name have no identifying information, and therefore confidence they are the same person is low. 10 = the names have similar information or are unique in some way, and while not matched automatically confidence they are the same person is very high; see Appendix 5 for further details). This argument is optional, if not included the function will use a default ‘confidence’ = 5.
The output of authors_refine() is an object in the R
workspace. We recommend saving this as a .csv file in the “output”
folder to avoid having to re-load and process files every session.
Example
- To accept the results of author disambiguation
without manual review (with default values for
sim_scoreandconfidence):
example_a_refined <- authors_refine(example_a_clean$review,
example_a_clean$prelim)- To accept the results of author disambiguation
without manual review (with user-modified
values for
sim_scoreandconfidence):
example_a_refined_mod <- authors_refine(example_a_clean$review,
example_a_clean$prelim,
sim_score = 0.70,
confidence = 4)- to save the final disambiguated (i.e., ‘refined’) dataset to the “output” folder of the RStudio Project:
write.csv(example_a_refined,"./output/example_a_refined.csv")2.2.2. Reviewing and correcting the results of disambiguation
There are two kinds of potential disambiguation errors. First,
diffent authors could be incorrectly assigned to the same groupID
number. Second, the same author could be incorrectly assigned multiple
groupID. Users can manually review the name disambiguation results for
potential errors using the ‘review’ output from
authors_refine that has been saved as ’_review.csv’
(Section 2.2 Example b). Appendix 3 provides a detailed description of
the information provided in this file and how it can be used to verify
name assignments. If disambiguation errors are found, they are corrected
on the _review.csv file as follows:
If different authors were incorrectly assigned the same groupID number: replace the number in the ‘groupID’ column of the incorrectly pooled author with the value from their ‘authorID’ column. Be sure to use the authorID value from the same row. Save the corrected .csv file as “correctedfile.csv” in the same location as the “_review.csv” file (i.e., the “output” folder).
If the same author was incorrectly assigned different groupID numbers: replace the number in the ‘groupID’ column of the incorrectly split name variants with a single ‘AuthorID’ number. We recommend using the lowest authorID number of the name variants being pooled. Save the corrected .csv file as “correctedfile.csv” in the same location as the “_review.csv” file (i.e., the “output” folder).
These corrections are uploaded using the
authors_refine() function, which then generates the
‘refined’ dataset used in analyses (see Section 2.2.3).
WARNING: Tests of our disambiguation algorithm
indicate it is very accurate, but no method is perfect and errors are
inevitable - especially as the number of author name variants increases.
However, finding these errors becomes increasingly challenging as the
number of references processed increases. This is because the number of
names on the _review.csv file will increase as more authors, and hence
author name variants, are identified. We strongly recommend
using code
we have written to streamline the process of reviewing the output of
authors_refine(). This code divides the list of
names to review into more manageable subgroups; any errors identified
are then corrected on the “_review.csv” file. The code and instructions
for using it are available at https://github.com/embruna/refsplitr_simplify_authors_review.
Example
Figure 3 is an example of the the first few rows and columns of the
‘review’ element of authors_clean(). Each row is the author
of a paper, with their name as it is on the author list (AF). Each
author has been assigned a unique authorID number as well assigned to a
groupID; the “match_name” column provides the name under which the
algorithm has grouped all of an author’s putative name variants when
assigning the groupID number.
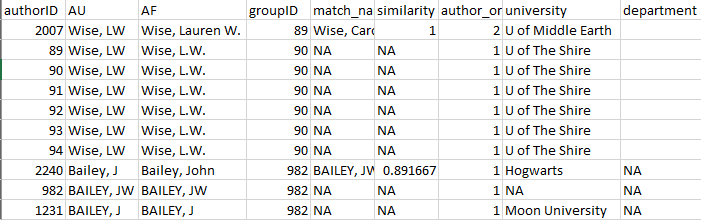
plot of chunk unnamed-chunk-31
Figure 3: First rows and columns from the review
element of authors_clean()
A review of this output indicates that refsplitr
assigned three authors sharing the last name “Bailey” and first initial
“J” to groupID number 982: John Bailey (authorID 2240), JW Bailey
(authorID 982), and J Bailey (authorID 1231; Figure 4). However, we know
that J Bailey at Moon University is a distinct individual that should
not be in the same group as the other two. Their incorrect groupID
number (982) should be replaced with their authorID number (1231).
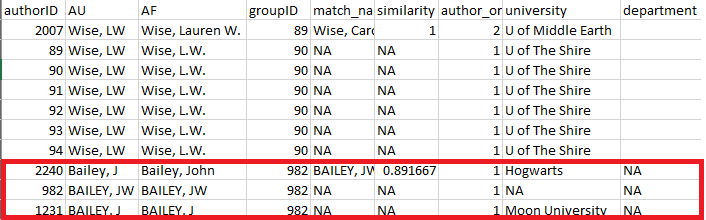
plot of chunk unnamed-chunk-32
Figure 4: review element of
authors_clean() highlighting three authors sharing the same
last and assigned the same groupID.
Further review reveals that there are two putative authors named LW Wise – one at U of Middle Earth (groupID 89) and one at U of the Shire (groupID 90; Figure 5). However, an online search reveals that this is actually the same author, who recently moved from one university to the other. The groupID for all of these records should therefore be changed to “89”.
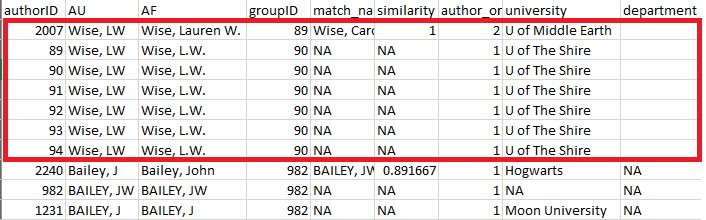
plot of chunk unnamed-chunk-33
Figure 5: review element of
authors_clean() highlighting the same author incorrectly
assigned to different groupID numbers.
Once these corrections have been made (Figure 6) and saved, the
changes can be incorporated using the authors_refine()
function (see Section 2.2.3).
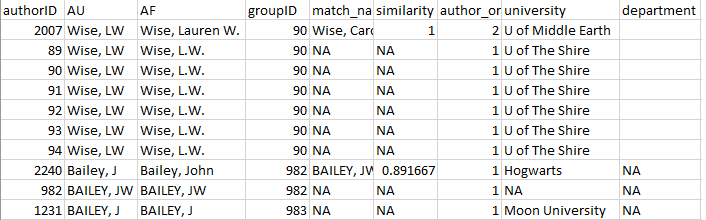
plot of chunk unnamed-chunk-34
Figure 6: Corrected version of the ‘review’ element
from authors_clean().
2.2.3. Uploading and merging the results of disambiguation
Corrections made to the “review” file are merged into the “prelim”
file using the authors_refine() function. It has four
arguments:
corrected: The corrected version of the “review” object. It must be an object, so read in the corrected .csv file before using this function.
prelim: The preliminary list of disambiguated author names created with
authors_clean(). Must be in an object.sim_score: The threshold for the similarity score below which authors are assigned different groupIDs. The range of sim_score is 0-1 (1 = names must be identical to be assigned to the same group). This argument is optional, if not included the function will use a default sim_score = 0.9.
confidence: The threshold for the confidence score below which authors are assigned different groupIDs. The range of ‘confidence’ is 0-10 (0 = the name and matched name have no identifying information, and therefore confidence they are the same person is low. 10 = the names have similar information or are unique in some way, and while not matched automatically confidence they are the same person is very high; see Appendix 5 for further details). This argument is optional, if not included the function will use a default ‘confidence’ = 5.
The output of authors_refine() is an object in the R
workspace, which can be saved by users as a .csv file in the “output”
folder.
Example
- To merge the changes made to the disambiguations, first load the .csv file with the corrections:
example_a_corrected <- read.csv("correctedfile.csv")The changes are then merged into the preliminary disambiguation:
example_a_refined <-authors_refine(example_a_corrected,
example_a_clean$prelim)- to save the final disambiguated (i.e., ‘refined’) dataset to the “output” folder of the RStudio project:
write.csv(example_a_refined,"./output/example_a_refined.csv")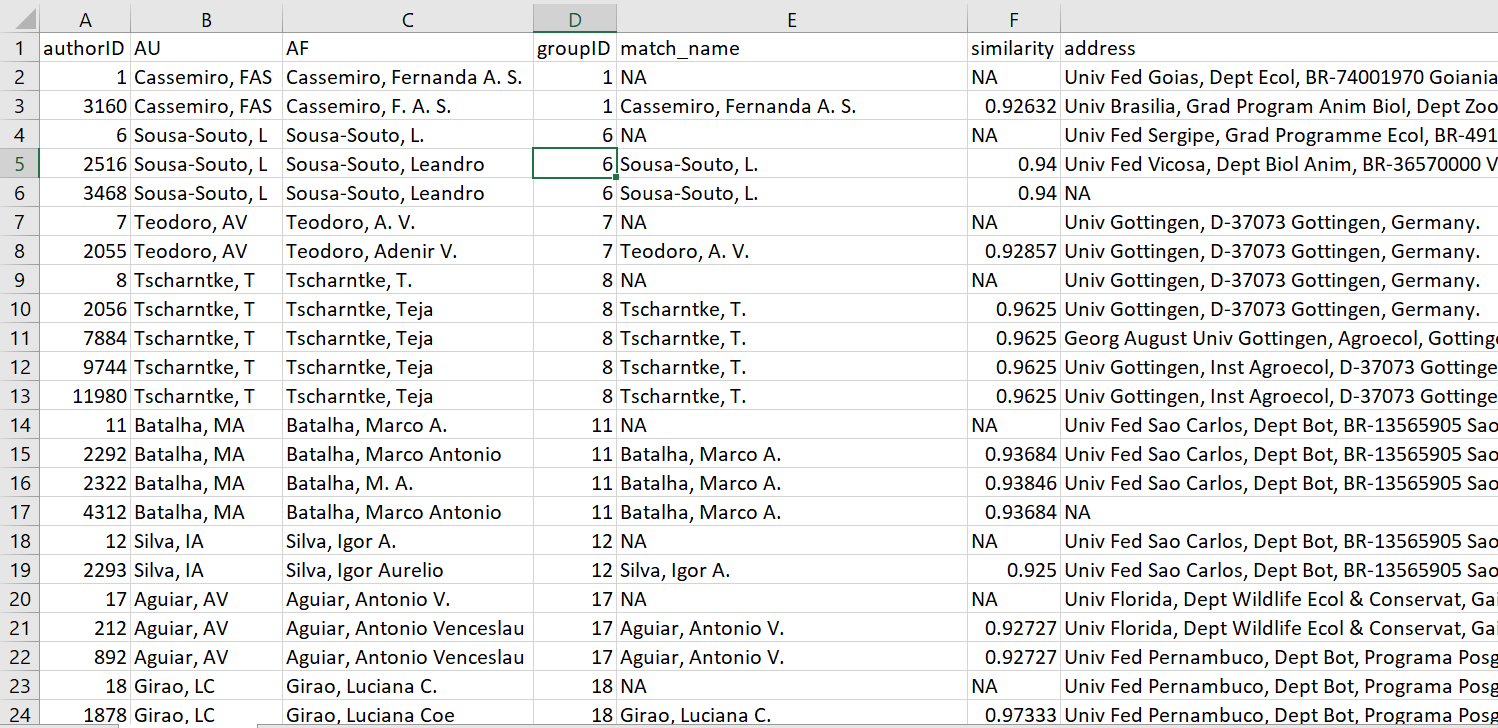
plot of chunk unnamed-chunk-38
Figure 7: authors_refine() output.
- User-selected values for
sim_scoreandconfidencecan be used to merge the changes made to the “review” file by adding the two relevant arguments to theauthors_refine()function:
example_a_refined_mod <- authors_refine(example_a_corrected,
example_a_clean$prelim,
sim_score = 0.70,
confidence = 4)2.3. Georeferencing author institutions
Users can georeference author’s institutions (latitude &
longitude) using the authors_georef() function. This
function has has three arguments:
data: The output created by
authors_refine(). Must be an object.address_column: A quoted character identifying the column name in which addresses are stored. This defaults to the
addresscolumn from theauthors_refine()output.google_api: Defaults to
FALSE. IfTRUEgeoreferencing will be conducted withggmapand the Google Maps API (paid service). IfFALSEgeocoding will be conducted with thetidygeocoderpackage, which uses the Nominatum service to access OpenStreetMap data. Note that when georeferencing large data sets, OSM requests users consider downloading and installing the complete database to query locally instead of using the API.
The output of authors_georef() is a list with three
elements: (1) addresses contains all records, (2)
missing_addresses contains the records that could not be
georeferenced, and (3) not_missing_addresses contains only
the records with georeferenced addresses.
WARNINGS:
The
authors_georef()function requires address be data type = character. If importing a .csv file with the results ofauthors_refine()for processing withauthors_georef(), be sure to include “stringsAsFactors = FALSE” in theread.csvcommand.The
authors_georef()function parses addresses from the Web of Science reference sheet and then attempts to calculate the latitude and longitude for them with the Data Science Toolkit. The time required to do so depends on the number of addresses being processed, the speed of the internet connection, and the processing power of the computer on which analyses are being conducted.This version of
refsplitr(v1.0) has difficulty differentiating between some geographically distinct installations of the same institution (e.g. the Mississippi State University Main Campus in Starkville vs the Mississippi State University Coastal Research and Extension located 250 miles away in Biloxi).
Example
- to georeference author institutions:
example_georef <-authors_georef(data=example_a_refined,
address_column = "address",
google_api = FALSE)Note that while this function is being executed a message will be printed every time a location is geoprocessed. These messages can be suppressed by modifying the function call as follows:
example_georef <-suppressMessages(authors_georef(
data=example_a_refined,
address_column="address",
google_api = FALSE))Registering with Google for an API key (NB: this is a paid service)
- Install and load the
ggmappackage
install.packages("ggmap")
library(ggmap)Register for a Google Geocoding API by following the instructions on the
READ MEof theggmaprepository.Once you have your API key, add it to your
~/.Renvironwith the following:
`ggmap::register_google(key = "[your key]", write = TRUE)`- You should now be able to use
authors_georef()as described in the vignette. WARNING:refsplitrcurrently has a limit of 2500 API calls per day. We are working on including the ability for users to select their own limits.
Remember: Your API key is unique and for you alone. Don’t share it with other users or record it in a script file that is saved in a public repository. If need be you can visit the same website where you initially registered and generate a new key.
2.4. Data Visualization: Productivity and Collaboration
refsplitr can generate five visualizations of scientific
productivity and couthorship. The functions that generate these
visualization use packages rworldmap (No. 1),
ggplot2 (Nos. 2,4,and 5), and igraph (No. 3).
Advanced users of these packages can customize the visualizations to
suit their needs. WARNING: The time required to render
these plots is highly dependent on the number of authors in the dataset
and the processing power of the computer on which analyses are being
carried out.
2.4.1. Visualization 1: Authors per country.
The plot_addresses_country() makes a map whose shading
of each country indicates the number of papers in the data set written
by authors based there. Note that there is no fractional authorship,
e.g., if a paper is written by a team of authors based in the USA,
Brazil, and Belgium, then that publication will count as one paper
towards the total for each of these countries.
The function has two arguments:
data: The ‘addresses’ element from the
authors_georef()object.mapRegion: the portion of the world map to display. Users can modify this argument to display the data on maps of either the entire world or focus on an individual region [options - “world”,“North America”,“South America”, “Australia”,“Africa”, “Antarctica”, “Eurasia”]. This argument is optional, if not included the function will use the world map as the default.
The output of plot_addresses_country() is plot from the
rworldmap package.
Example
- Author records plotted on a world map
plot_addresses_country <- plot_addresses_country(example_georef$addresses)
plot of chunk unnamed-chunk-42
Figure 8: Plot of the countries in which the authors in the dataset are based, with shading to indicate the number of authors based in each of country.
2.4.2. Visualization 2: Author locations
The plot_addresses_points() function plots the
geographic location of all authors in the dataset.
The function has two arguments:
data: This is the ‘addresses’ element from the
authors_georef()object.mapCountry: Users can modify this argument to display the data on either a map of the entire world or focus on a specific country [e.g., “USA”,“Brazil”,“Nigeria”]. This argument is optional, if not included the function will use the world map as the default.
The output of authors_georef() is a ggplot object.
Example
- Mapped location of author institutions (global).
plot_addresses_points <- plot_addresses_points(example_georef$addresses)
plot_addresses_points
plot of chunk unnamed-chunk-43
- Mapped location of author institutions (national).
Figure 9: Figure indicating the georefeenced locations of all authors in the dataset
plot_addresses_points <- plot_addresses_points(example_georef$addresses,
mapCountry = "Brazil")
plot_addresses_points
plot of chunk unnamed-chunk-45
Figure 10: Figure indicating the georefeenced locations of authors in the dataset with institutional addresses in Brazil.
2.4.3. Visualization 3: Base coauthorship network
The plot_net_coauthor() function plots a co-authorship
network in which the nodes are the countries in which authors are
based.
The function has one argument:
-
data: This is the ‘addresses’ element of the
authors_georef()object.
This function has one output, a plot, built in
igraph.
Example
- Coauthorship networked based on the country in which coauthors are based.
plot_net_coauthor <- plot_net_coauthor(example_georef$addresses)
plot of chunk unnamed-chunk-46
plot_net_coauthor
#> IGRAPH 59d2e4d UNW- 15 27 --
#> + attr: name (v/c), label (v/c), label.color (v/c), label.cex
#> | (v/n), size (v/n), frame.color (v/l), color (v/c), weight
#> | (e/n)
#> + edges from 59d2e4d (vertex names):
#> [1] argentina--mexico argentina--usa
#> [3] australia--brazil australia--germany
#> [5] australia--mexico australia--usa
#> [7] belgium --brazil belgium --usa
#> [9] brazil --could not be extracted brazil --germany
#> [11] brazil --mexico brazil --usa
#> + ... omitted several edgesFigure 11: Plot of the coauthorship network for authors of articles in the dataset.
2.4.4. Visualization 4: Mapped Coauthorships by Author Country
The plot_net_country() function plots a georeferenced
coauthorship network in which the nodes are the countries in which
co-authors are based. The size of the circle for each country is scaled
by the number of authors based in that country.
The function has four arguments:
data: This is the ‘addresses’ element from the
authors_georef()object.lineResolution the resolution of the lines drawn between countries; higher values will plot smoother curves. This argument is optional, if not included the function will use a default value = 10.
mapRegion: the portion of the world map to display. Users can modify this argument to display the data on maps of either the entire world or focus on an individual region [options - “world”,“North America”,“South America”, “Australia”,“Africa”, “Antarctica”, “Eurasia”]. This argument is optional, if not included the function will use the world map as the default.
lineAlpha: The transparency of the lines connecting countries. Values can range from 0-1, with lower values making line more transparent. This argument is optional, if not included the function will use a default value = 0.5.
The output of plot_net_country() is a list in the R
workspace. The $plot element contains a ggplot object.
Because the ability to customize $plot is limited, three
datasets are provided so that users can generate and customize their own
plots:
The
$data_pathelement contains the data for the connecting lines.The
$data_polygonelement contains the data for the country outlines.The
$data_pointelement contains the data for the circles on the map.
Example
- Mapped coauthorship network based on the countries in which authors are based.
plot_net_country <- plot_net_country(example_georef$addresses)
#> Error in Ops.data.frame(fromC, toC): '+' only defined for equally-sized data frames
plot_net_country$plot
#> Error in plot_net_country$plot: object of type 'closure' is not subsettableFigure 12: Map showing the coauthorship connections between countries.
2.4.5. Visualization 5: Mapped Coauthorships by Author Address
The plot_net_address() function is used to plot a
georeferenced coauthorship network based on author institutional
addresses. WARNING: This function can create a large
data set (i.e., 100s of MB) and may takes several minutes to complete.
Take into account the system resources available when running it, and be
patient!
The function has four arguments, three of which only need to be included if changing the default settings: :
data: This is the addresses element from the
authors_georef()output.mapRegion: the portion of the world map to display. Users can modify this argument to display the data on maps of either the entire world or focus on an individual region [options - “world”,“North America”,“South America”, “Australia”,“Africa”, “Antarctica”, “Eurasia”]. This argument is optional, if not included the function will use the world map as the default.
lineResolution the resolution of the lines drawn between countries; higher values will plot smoother curves. This argument is optional, if not included the function will use a default value = 10.
lineAlpha: The transparency of the lines connecting countries. Values can range from 0-1, with lower values making line more transparent. This argument is optional, if not included the function will use a default value = 0.5.
The output of plot_net_address() is a list in the R
workspace. The $plot element contains ggplot object.
Because the ability to customize $plot is limited, three
datasets are provided so that users can generate and customize their own
plots:
- The
$data_pathelement contains the data for the connecting lines. - The
$data_polygonelement contains the data for the country outlines. - The
$data_pointelement contains the data for the circles on the map.
Example
- Coauthorship network based on the geographic locations of coauthor institutions.
plot_net_address <- plot_net_address(example_georef$addresses)
plot_net_address$plot
plot of chunk unnamed-chunk-48
Figure 13: Plot showing the network between individual author locations.
Acknowledgments
Support for the development of refsplitr was provided by
grants to E. M. Bruna from the Center for Latin American Studies
and Informatics
Institute at the University of
Florida.
References
Aria, M. & Cuccurullo, C. (2017) bibliometrix: An R-tool for comprehensive science mapping analysis. Journal of Informetrics, 11(4): 959-975. DOI: 10.1016/j.joi.2017.08.007
Fortunato, S., C. T. Bergstrom, K. Barner, J. A. Evans, D. Helbing, S. Milojevic, A. M. Petersen, F. Radicchi, R. Sinatra, B. Uzzi, A. Vespignani, L. Waltman, D. Wang, & A.-L. Barabasi (2018). Science of science. Science, 359: eaao0185. DOI: 10.1126/science.aao0185
Larivière, V., Ni, C., Gingras, Y., Cronin, B., & Sugimoto, C. R. (2013). Bibliometrics: Global gender disparities in science. Nature News, 504(7479): 211-213. DOI: 10.1038/504211a
R Core Team (2019). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
Smalheiser, N. R., & Torvik, V. I. (2009). Author name disambiguation. Annual Review of Information Science and Technology, 43(1): 1-43. DOI: 10.1002/aris.2009.1440430113
Smith, M. J., Weinberger, C., Bruna, E. M., & Allesina, S. (2014). The scientific impact of nations: Journal placement and citation performance, PLOS One 9(10): e109195. DOI: 10.1371/journal.pone.0109195
Strotmann, A. and Zhao, D., (2012). Author name disambiguation: What difference does it make in author based citation analysis?. Journal of the Association for Information Science and Technology, 63(9): 1820-1833. DOI: 10.1002/asi.22695
Sugimoto CR, Larivière V. (2018). Measuring Research: What Everyone Needs to Know?. Oxford University Press, Oxford, UK. 149 pp. ISBN-10: 9780190640125
Westgate, M. J. (2018). revtools: bibliographic data visualization for evidence synthesis in R. bioRxiv:262881. DOI: 10.1101/262881
Appendix 1: Guide to downloading reference records from the Web of Science.
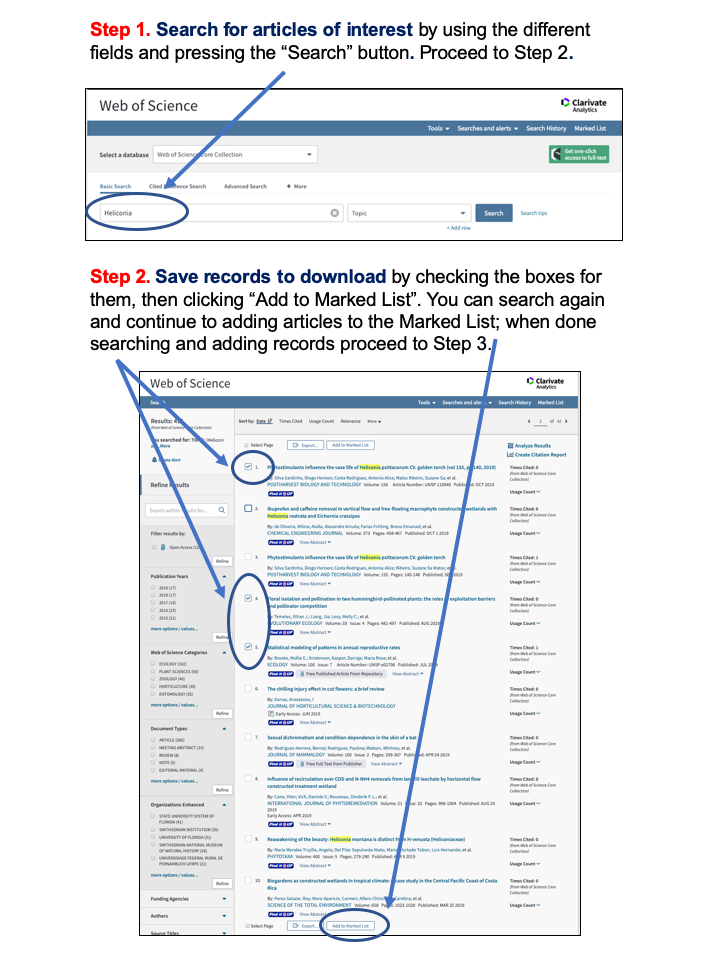
plot of chunk unnamed-chunk-49
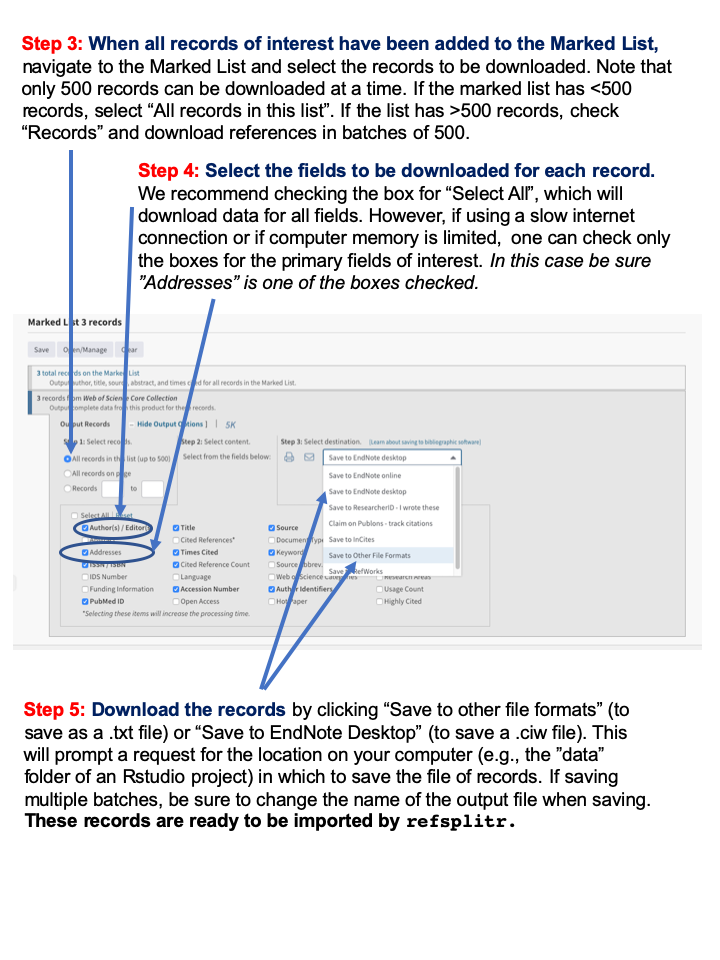
plot of chunk unnamed-chunk-49
Figure 13: Web of Science Download Instructions
Appendix 2: Web of Science Data Field Definitions
| Column Heading | Definition |
|---|---|
| filename | file from which records were imported |
| AB | Abstract |
| AF | Author Full Name |
| AU | Authors |
| CA | Consortium Author |
| BP | Beginning Page |
| C1 | Author Address |
| CR | Cited References |
| DE | Author Keywords |
| DI | Digital Object Identifier (DOI) |
| EM | E-mail Address |
| EP | Ending Page |
| FN | File Name |
| FU | Funding Agency and Grant Number |
| PD | Publication Date |
| PG | Page Count |
| PT | Publication Type (J=Journal; B=Book; S=Series; P=Patent) |
| PU | Publisher |
| PY | Publication Year |
| RI | ResearcherID Number |
| OI | Open Researcher and Contributor ID Number (ORCID ID) |
| PM | PubMed ID |
| RP | Reprint Address |
| SC | Research Areas |
| SN | International Standard Serial Number (ISSN) |
| SO | Publication Name |
| TC | Web of Science Core Collection Times Cited Count |
| TI | Document Title |
| UT | Accession Number |
| VL | Volume |
| WC | Web of Science Categories |
| Z9 | Total Times Cited Count2 |
| refID | a unique identifier for each article in the dataset assigned by refnet |
1the following Web of Science data fields are only
included if users select the include_all=TRUE option in
references_read(): CC, CH, CL, CT, CY, DT, FX, GA, GE, ID,
IS, J9, JI, LA, LT, MC, MI, NR, PA, PI, PN, PS, RID, SU, TA, VR.
2Includes citations in the Web of Science Core Collection, BIOSIS Citation Index, Chinese Science Citation Database, Data Citation Index, Russian Science Citation Index, and SciELO Citation Index.
Appendix 3: Reviewing and correcting author name
assignments by authors_clean()
The information in the Table below is provided by the
authors_clean() function to help users assess the validity
of groupID assignments made by refsplitr’s disambiguation
algorithm. However, finding any errors in disambiguation becomes
increasigly challegning as the number of references processed increases.
This is because the number of names on the _review.csv file will
increase as more authors, and hence author name variants, are
identified. We strongly recommend using code
we have written to streamline the process of reviewing the output of
authors_refine(). This code divides the list of names to
review into more manageable subgroups; any errors identified are then
corrected on the “_review.csv” file. The code and instructions for using
it are available at https://github.com/embruna/refsplitr_simplify_authors_review.
| Field | Definition |
|---|---|
| authorID | AuthorID is a unique identifier for each name in the database (i.e. every author of every paper; the initial assumption of refnet’s disambiguation algorithm is that all authors of all articles are different individuals). |
| AU | Authors |
| AF | Author Full Name |
| groupID | This indicates which names (i.e. AuthorID numbers) have been grouped together under a single groupID number because they are believed to be the same person. Because disambiguation is performed iteratively. The lowest authorID number in a group will always be used as the groupID. |
| match_name | The name under which the algorithm groups all of an author’s putative name variants. |
| similarity | The similarity score between the two records. |
| author_order | The location on the article’s list of authors where this specific author is found |
| address | The author’s complete address as listed in the record for an article. |
| university | The author’s department, if one is listed in the address |
| department | The author’s department, if one is listed in the address |
| short_address | The author’s street address |
| postal_code | The author’s postal code |
| country | The country in which an author’s institution is based |
| RP_address | The reprint address, if present |
| RI | The author’s Thomson-Reuters Researcher ID number in the WOS record for an article (if they have one). |
| OI | The author’s ORCID ID number in the record for an article (if they have one). |
| EM | The author’s email address in the WOS record for an article (if it lists one). |
| UT | Accession Number |
| refID | An id number given to each reference |
| PT | Publication Type (J=Journal; B=Book; S=Series; P=Patent) |
| PY | Publication Year |
| PU | Publisher |
Appendix 4: Overview of the refsplitr
author name disambiguation algorithm.
Name disambiguation is a complex process that is the subject of
active research. There are a variety of approaches to disambiguation in
large datasets; here we describe the algorithm for parsing author
addresses and disambiguating author names with the
authors_clean() function.
There are three primary difficulties in assigning authors to their products in bibliometric databases like the Web of Science. First, not all authors have a unique identifier such as an ORCID iD (ORCID) or ResearcherID (RID). Second, an author’s name can vary over time. It can also be reported inconsistently across journals. For instance, while author last names are always reported, the first names might only be represented by initials and middle names (if authors have one) might not be reported or might only be stored as a middle initial. Finally, information in the “address” field can have inconsistent structures. In addition, only after 2008 did Web of Sceince records directly link each author with their institutional address. As a result, for pre-2008 Web of Science records it can be difficult to relate each author with their institutional address (the same is true for email addresses). In these cases, we have no way to reliably match addresses to authors using the information in the reference record and therefore insert ‘Could not be extracted’ in the address field. This does not mean an address was not listed or cannot be assigned after manual inspection - only that there was no way to discern to which author the address belongs. Coupled with changes in author addresses as they change institutions, this the inconsistent or incomplete information associated with author addresses makes disambiguating names difficult.
To address this we’ve created a process to identify clusters or common authors by iteratively building webs of authors using any available information to link groups together. In this way we do not require an entry to contain all relevant fields, but can nevertheless create likely groupings and then refine them by throwing out obvious spurious connections. In the case of authors with ORCID and RID numbers, identifying commonalities is quite easy, and we hope that authors will continue to sign up for these identifiers to facilitate disambiguation.
The first step in our disambiguation process is matching all groups together with common ORCID and RID numbers. The remaining entries go through a series of logical rules to help match the author with only likely entries. Throughout this analysis we assume that every author has a complete last name and require the author’s record contain any two of the following: first name, middle name, address, or email (the first and middle name can be initials). Requiring this type of information means we cannot match authors that do not contain any of this extra information, and so we do not group entries with no middle name, address, AND email, but instead call them their own group and skip them from the following analysis. To lower calculation times, as the algorithm attempts to match each entry it creates a subset of possible matching combinations of last and first names, and then attempts to match them against middle initials, address, and email addresses.
- note regarding email addresses - Similar to street addresses, email addresses are often stored inconsistently with no direct link between a specific author and specific email address. In these cases, we run a Jaro-Winkler distance measurement that calculates the amount of transpositions required to turn one string (an author name) into another (an email address). This works very well when email addresses are in a standard format (e.g., “lastname”.”firstname” @ university.edu). We match author names to each email and use a threshold percentage of 0.70. If no names match up below this threshold we disregard the email and leave the field blank in the author name.
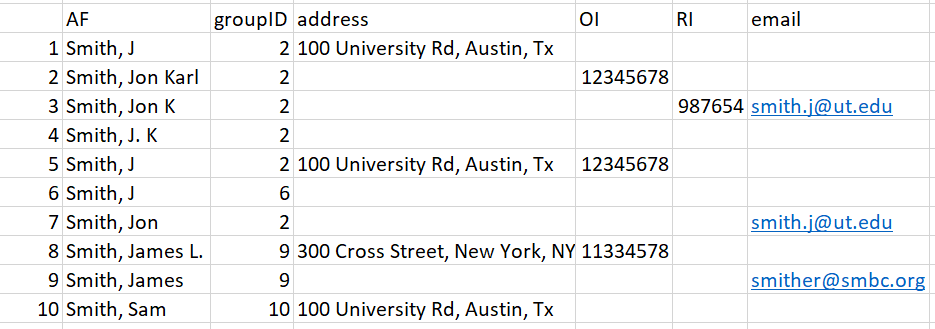
Below is an example of how the algorithm processes a sample data set.
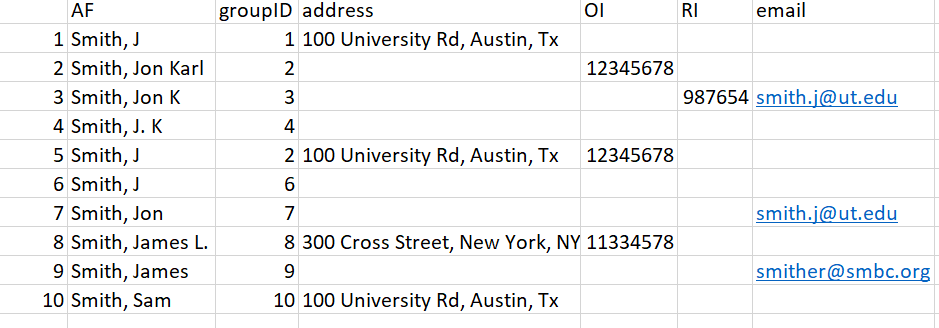
plot of chunk unnamed-chunk-52
Figure 14: Example dataset.
In this dataset we have 10 authors, with a mixture of incomplete columns for each row. Rows 2 and 5 were given the same groupID priori because of their matching ORCID. We’ll walk through the remaining entries and how the algorithm matches names together.
To lower the number of Type II errors we build a dataset of possible matches for each author; each entry in this subset must adhere to the following guidelines:
In all cases last names must match exactly (case insensitive). This means misspelled names will likely not get matched unless they have an ORCID or RID against which to match.
First names must match; in the case they only have an initial then that initial must match.
Middle names must match; in the case they only have an initial they must match. Cases of authors with no middle name are allowed if the author’s record has another piece of identifying information (e.g., an address or email address).
Entry 1. In our test data we will start trying to match the first entry “Smith, J” in row 1. By subsetting with the above rules, we’d be matching the first row against rows 2, 3, 4, 5, 6, 7, 9:
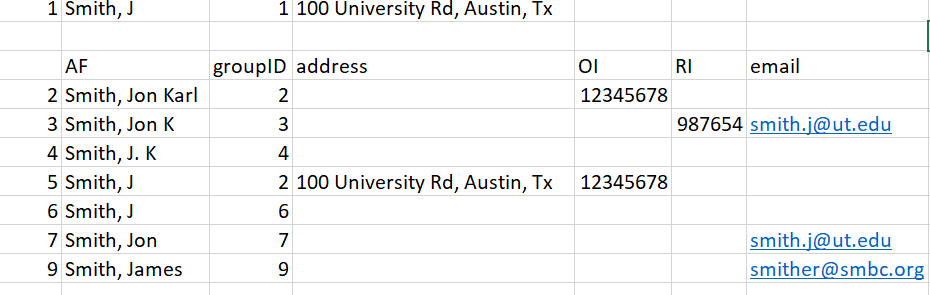
plot of chunk unnamed-chunk-53
Figure 15: Figure for entry 1
Once we have our subset of possible similar entries, we match the existing info of row 1 against the subset. The entry only needs to match one extra piece of information - either address, email, or middle name. If it matches we assume it is the same person, and change the groupID numbers to reflect this.
In our test data, there is only one piece of information we can match against - address, which makes the obvious match Row 5. We therefore change the groupID for our entry to groupID = 2. This gives us three entries with groupID = 2.
Entry 2. Row 2 was already matched to another group using ORCID prior, so it is skipped.
Entry 3. Row 3 has 2 unique identifying pieces of information: A middle initial and an email. This subset is smaller because we have a middle initial to filter out the Smith, J.L entries:
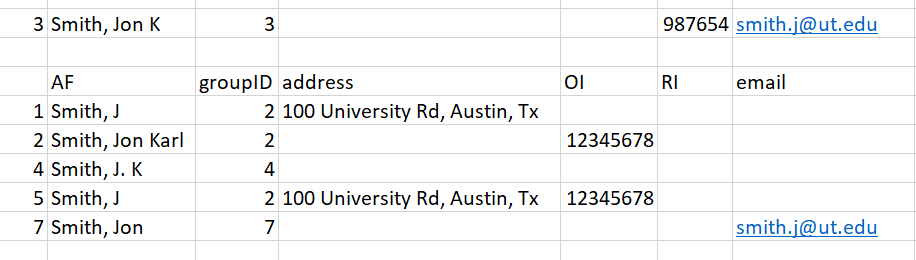
plot of chunk unnamed-chunk-54
Figure 16: Figure for entry 3
Matching this information against our subset, the two possible matches are Row 2 and Row 7. In cases with multiple matches we choose the entry with the lowest number, as it is likely to have been grouped already. However, even if the entry in Row 7 was chosen as a match, it will eventually be matched up to groupID = 2. When a ‘parent’ groupID is changed in this way, all the ‘child’ entries are changed to match the new groupID as well. As such, the decision is partially arbitrary.
Entry 4 - This entry gets assigned groupID = 2 as well because it has a matching middle initial with Row 2 and Row 3:

plot of chunk unnamed-chunk-55
Figure 16: Figure for entry 4
Entry 5 - Row 5 has already been matched with ORCID, so it is skipped.
Entry 6 - Row 6 has no additional matching information - no middle name, address, or email. There is therefore no way to reliably know which ’Smith, J` it belongs to, so the entry is assumed to be its own unique group and is skipped.
Entry 7 - Entry 7 has one unique identifier: an email address. It gets matched to the entry in Row 3 and therefore is assigned groupID = 2.
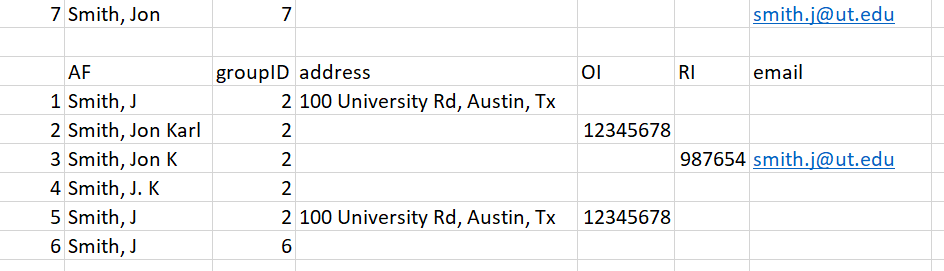
plot of chunk unnamed-chunk-56
Figure 17: Figure for entry 7
After these first 7 entries, we’ve correctly matched all likely ‘Smith, Jon Karl’ together and created the ‘Jon Karl Smith’ complex. Now we’ll move onto a situation where we have inadequate information, and must therefore run a Jaro-Winkler distance analysis to decide the likely match.
Entry 8 - This novel entry has two unique pieces of information: a middle initial and an ORCID. We know the ORCID did not match any previous entries, and the middle initial does not match up with any of the ‘Smith’ names in our record.
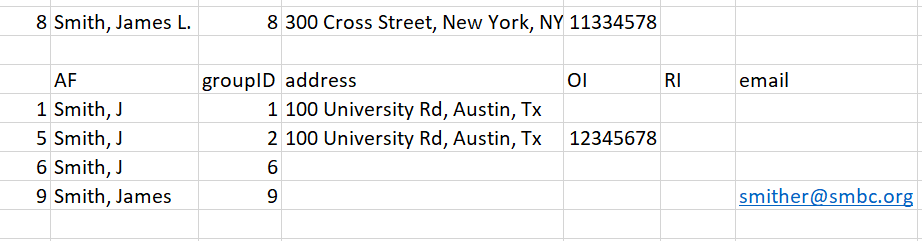
plot of chunk unnamed-chunk-57
Figure 18: Figure for entry 8
Because there are no suitable matches using initial criteria, we instead match the entry by calculating a Jaro-Winkler distance between the name in Row 8 and the author names in our subset. The results are: 0.9 [Row 1], 0.9 [Row 5], 0.9 [Row 6], and 0.96 [Row 9]. Therefore, the most likely match for the name ‘Smith, James L’ is the name in Row 9 (‘Smith, James’). We change the groupID to 9, and set aside this entry for the user to manually review later.
Entry 9 - Results in the same result as 8 and is matched to entry 8 which already has the groupID of 9.
Entry 10 - This entry has no matching names and results in no change to the groupID number.
plot of chunk unnamed-chunk-58
Figure 19: Figure for Entry 10
Thus our final results are:

plot of chunk unnamed-chunk-59
Figure 20: Final Results.
As a final check against our created groupings, we attempt to prune groupings by reanalyzing if First name, last name, and middle names match. This is because matching entries using incomplete info occasionally creates novel situations where two similar names are called the same groupID if they have similar other information like same first name and the same address. Additionally, the imperfect matching of email addresses occasionally matches up relatives or significant others who publish together with the incorrect email creating a mismatched complex. This final pruning step separates the groups entirely by name. It should be noted this situation in general is rare.
This step is not necessary in our example data as all names in each grouping were logical. In our final data set, we have therefore identified 4 likely complexes (Smith, Jon Karl; Smith, J; Smith, James; and Smith Sam). Entries 8 and 9 were matched together and require hand checking as no novel information was used. This results in this data.frame being outputted separate from the master authors data.frame:
Appendix 5: Overview of the refsplitr
confidence score calculation.
To help the user identify potential false positives and negatives of author matches, we calculate a confidence score metric. This metric is calculated on names who could not be matched automatically by our algorithm above, but were matched using a ‘best guess’ approach using the available information and the Jaro Winkler textual matching. Names matched using this method suffer from higher false positive rates because we lacked proper information to match them directly. This metric is a 0 - 10 rating where 0 means we have no information that would lead us to be confident on the match, and 10 meaning based on the available information we are very confident the name is correct (but not enough to have matched automatically). Names are given a score using the following criteria:
4 - The postal code matches
2 - The country matches
2 - The last name is longer than 10 characters
2 - The last name contains a dash (like when there are two
surnames)
1 - The last name is longer than 6 characters but less than 11.
1 - Either name has a middle initial
1 - Either name has a full first name
1 - For each instance a name or match name contains a university or
email (And thus easier to find a match using Google).
The maximum score is 10 regardless of the total scores sum.
Using this score criteria we find that >7 are very likely always correct, scores >=5 but <7 are nearly always correct, and <5 are variable in their accuracy.
This can help guide the user when manually checking reviewed names,
but can also speed up the process when running analysis. Users can set
their confidence threshold in authors_refine depending on
their tolerance for false positives in their analysis without needing to
manually check all reviewed names.